本周介绍了注意力机制 (Attention mechanism),这个机制可以帮助模型理解给定一个输入后应该“关注”哪儿,同时学习如何处理语音识别和音频数据。
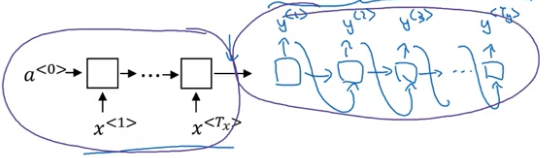
sequence to sequence 模型
基本模型
将法语变成英语:

输入编码器,然后用解码器输出:
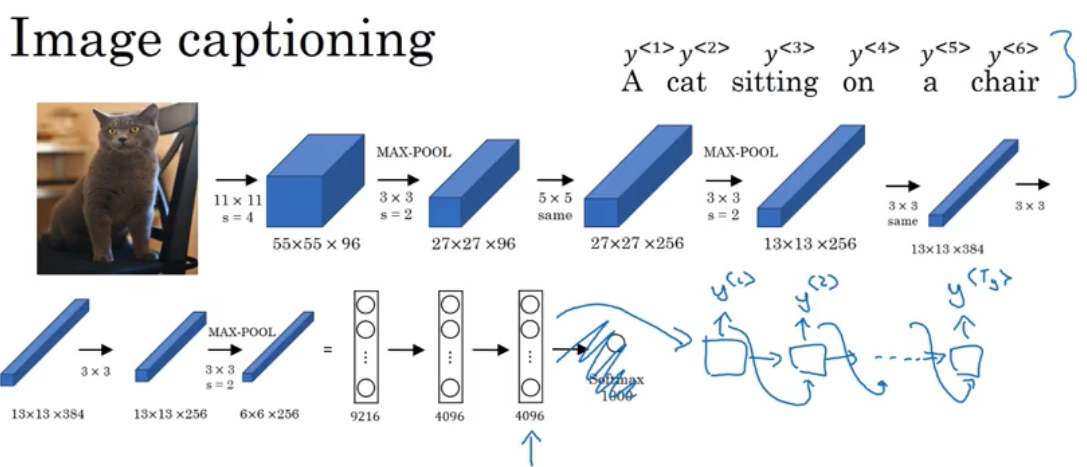
另一个例子是图像标注解释,目标是输入一张图片,输出这张图片的解释文字,首先将图片通过一个预训练好的神经网络,例如 AlexNet,它可以学习输入图片的编码结果,最后输出一个图片的特征序列,这个网络可以作为上图中的编码器部分。将这个 4096 维的特征序列输入解码器,输出文字。
如何挑出可能性最大的输出序列
首先我们看看序列-序列模型和语言模型的区别。
我们使用语言模型估计一个句子的概率 $P(y^{<1>},…,y^{< T_ y >})$ :

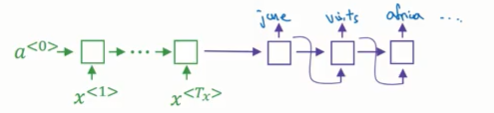
而机器翻译模型的解码器部分就和语言模型一样,而绿色的编码器部分输出相当于语言模型中的 $a^{< 0 >}$,如下图所示:
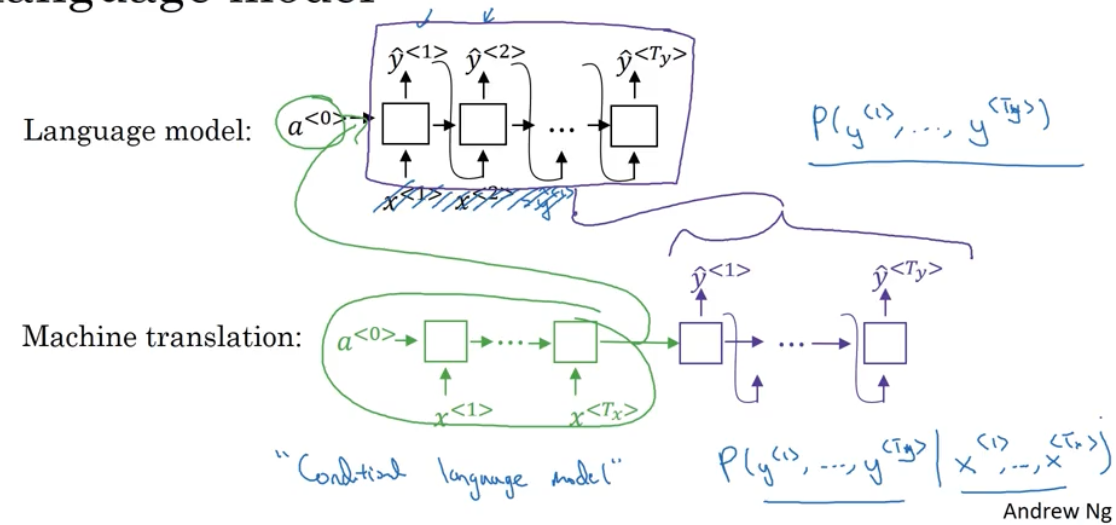
由于编码器的输出相当于 $a^{< 0 >}$,所以基本的语言模型变成了在 $x^{<1>},x^{<2>},…,x^{< T _ x >}$的条件下的语言模型,称之为“条件语言模型”。
当使用该模型时,输入一个法语句子 x,在这个句子的条件下生成对应的英语句子,但问题是我们每次都可能得到不同的翻译,我们需要做的是找到一个句子使得这个条件概率最大化。

如何找到可能性最大的句子?一般使用定向搜索 beam search,见下节。
为何不使用贪婪搜索?
贪婪搜索指的是先选出可能性最大的第一个词 $\hat y^{<1>}$,然后选出可能性最大的第二个单词,然后第三,第四……假设我们有两个句子:
- Jane is visiting Africa in Septemper.
- Jane is going to be visiting Africa in September.
它们是一句法语的两种翻译,明显第一种更好,但是当前两个单词是 Jane is 时,going 出现的概率比 visiting 会更大,因为 going 是更加常见的单词,所以贪婪搜索是不合适的。
Beam search 集束搜索
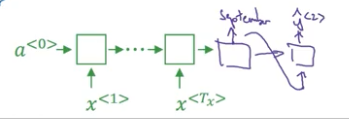
假设我们要实现输入法语 Jane visite l’Afrique en september. 最佳输出为 Jane is visiting Africa in September. 如何在众多输出中选出这个最佳的句子?
我们有一个 10000 词的词汇表 {a,aaron,…,in,…,jane,…,september,…,zulu},设置束宽 beam width 为 B = 3. 即一次挑选出三个可能的词。
第一步
首先我们将编码器的输出输入到解码器里,得到 $ \hat y^{<1>}$,它是一个 10000 维的向量,代表了给定法语单词 x,输出第一个词的概率 $P(y^{<1>}|x)$。
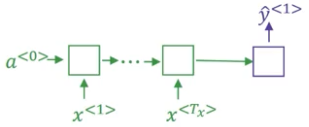
根据 $P(y^{<1>}|x)$,挑出概率值最大的 B (这里取 3) 个单词,例如 in、jane、September。
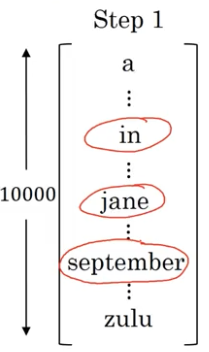
第二步
接下来我们确定第二个单词是什么。
对于 $y^{<1>}=“in”$,我们将单词 in 采样到下一层,得到 $ \hat y^{<2>}$,它同样是一个 10000 维的向量,代表了给定 $x,y^{<1>}$,输出第二个词的概率 $P(y^{<2>}|x,“in”)$。
接着计算前两个单词的联合概率 $P(“in”,y^{<2>}|x)=P(“in”|x)P(y^{<2>}|x,“in”)$,也即在给定法语单词 x 的情况下,输出 $“in”,y^{<2>}$ 的概率。
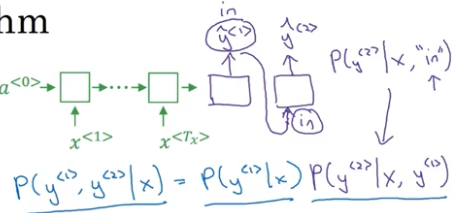
接着对 $y^{<1>}=“jane”$,进行同样的操作,得到 $P(“jane”,y^{<2>}|x)$。
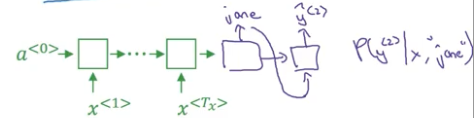
接着对 $y^{<1>}=“September”$,进行同样的操作,得到 $P(“September”,y^{<2>}|x)$。
对于三个单词 in、jane、September 而言,每个单词后面有 10000 种可能,所以总共有 30000 种可能,在这 30000 种可能里根据 $P(y^{<1>},y^{<2>}|x)$,挑选出 B = 3 种概率最大的组合,如下图红框所示。
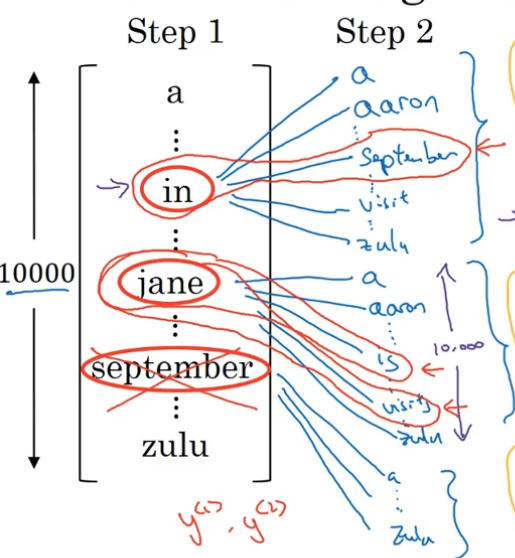
第三步
现在我们内存里储存了 “in september”、“jane is”、“jane visits” 三种组合的 $P(y^{<1>},y^{<2>}|x)$。
重复第二步的操作直到生成结束符<EOS>:
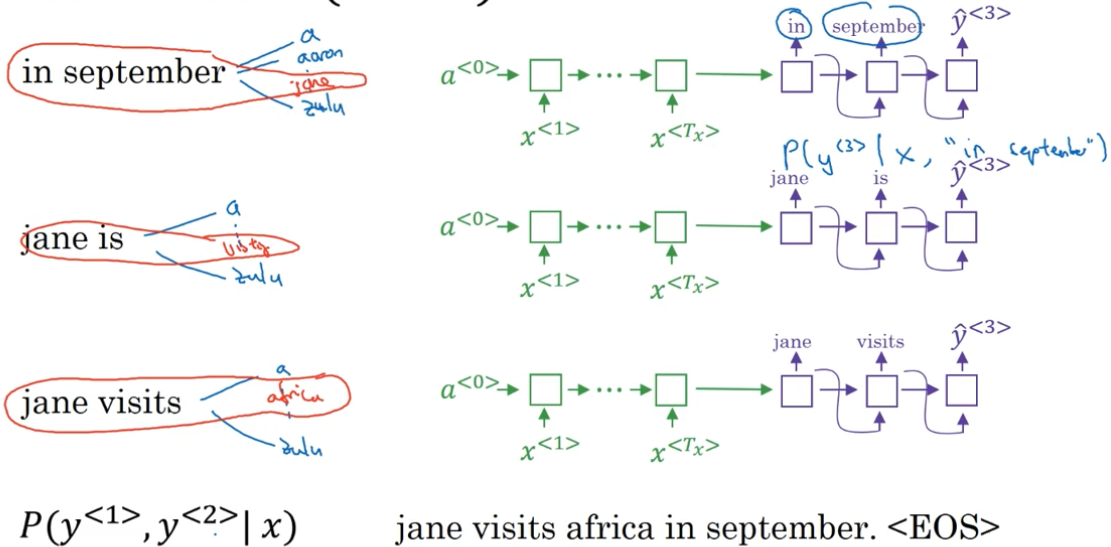
当 B = 1 时,集束搜索退化为贪婪搜索。
集束搜索改进
长度归一化
集束搜索的目标是找到使得 $P(y^{<1>},…,y^{< T _ y >}|x)$ 最大的句子 y,即:
由于上式是由许多个小于1 的概率值相乘,所以最后会得到一个非常非常小的数,导致数值下溢,意思是无法用浮点数准确表达,所以在实际中我们会将上式取对数,即:
还有一个问题就是,由于上式是由多个概率相乘得到的,如果一个句子越长,那么乘得项就越多,最后的概率也越低,也就是说,这个函数倾向于选择更短的输出,我们可以进行一个改动:
- 其中 $\alpha$ 决定了对长度进行归一化的柔和程度,1 表示完全的归一化,0 表示完全没有归一化
如何选择束宽 B
一般 B 越大,结果更好,但是速度更慢,在生产系统中,B 在 10~100 左右,而研究人员为了发论文很多使用 1000~3000 的束宽 B.
集束搜索的错误分析
单个样例分析
当我们对算法进行测试时,我们需要将模型生成的翻译句子与人工翻译的句子进行对比,算法有时候会生成错误的句子,这种错误的来源有两个方面:有可能是集束搜索产生了错误,束宽 B 选择的不正确;也有可能是 RNN 模型导致了错误。为了知道到底是哪个部分出现了问题并集中时间改进那个部分,我们需要对结果进行误差分析。
例如我们要翻译下面这个法语句子:Jane visite l’Afrique en septembre.
高质量的人类翻译:Jane visits Africa in September.(将这个句子记为 $y^*$)
RNN + 集束搜索生成的错误翻译:Jane visits Africa last September. (将这个句子记为 $\hat y$)
现在我们需要计算得到人类翻译的句子的概率 $P(y^*|x)$ 和得到模型预测的句子的概率 $P(\hat y|x)$,比较两者的大小。
如何计算呢?
我们首先看看 RNN 计算的是什么,
假设要计算得到 “Jane visits Africa in September.” 这个句子的概率就是:
注意:实际上,由于 $ y ^ * $ 和 $ \hat y $ 长度不同,为了比较 $ P(y ^ *| x) $ 和 $ P(\hat y |x) $ 的大小,必须求长度归一化后的概率,这里先省略这一步
接下来有两种情况:
情况一:$P(y^*|x) >P(\hat y |x)$
集束搜索是根据 $P(y|x) $ 决定最终输出的, $ P(y^*|x) >P(\hat y |x) $,按理说最终集束搜索应该会选择概率值更大的 $y^* $,但是真实的输出是 $\hat y $,这就说明在这种情况下,集束搜索出问题了,没有给你最大化 $P(y|x) $ 的那个句子 y.
情况二:$P(y^*|x) \leqslant P(\hat y |x)$
虽然 $y^* $ 是比 $\hat y $ 更好的翻译,但是 RNN 预测得到句子的概率 $P(y^*|x) \leqslant P(\hat y |x) $,也就是说 RNN 更有可能输出更差的 $\hat y $ 而不是更好的 $y ^* $,这就说明在这种情况下,RNN 模型是有问题的。
错误分析过程
查看开发集并找出算法在开发集中的错误翻译(“错误”指得是跟人类的翻译比较差的多),记录每个样例的 $P(y^*|x)$ 和 $P(\hat y |x)$,并进行比较,按照上述两种情况找出导致这个样例子错误的原因,集束搜索还是 RNN?记录下来。

这样就能通过错误分析找出哪一部分错误是集束搜索引起的,哪一部分错误是 RNN 模型引起的。当你发现集束搜索引起了更多的错误时,我们因该努力增加束宽 B,反之,如果发现 RNN 是错误所在,可以试着加上正则化,获取更多的训练数据,或者换一个网络结构。
模型评估—— Bleu Score
对于一个法语句子,可能有多个很好的英语翻译,那么如何在有几个质量好的翻译结果的情况下 评估机器翻译系统呢?对于只有一个正确答案的图像识别, 只需要测量准确度就行了,那么如何在有多个好结果的情况下测量准确度呢?传统的方法是利用 BLEU(双语评估替补) 指数。
假设我们有一个法语句子和两个人类的参考翻译:
- French: Le chat est sur le tapis.
- 参考 1 : The cat is on the mat.
- 参考 2 : There is a cat on the mat.
Unigram(单词) Bleu score
假设模型输出的结果为:
- the the the the the the the
一种计算结果精确度 Precision 的方式为:看这个句子的每个单词是否出现在参考翻译(1 或 2)中,如果出现了则记为 1,否则记为 0,将所有单词的计数相加再除以句子的单词总数就是精确度了,则上面那个句子的 Precision 为 $\frac{7}{7}$ ,但是明显它是一个很糟糕的翻译,所以有改进的精确度计算方式:对于句子的每个单词(重复的不算),看该词最多出现在参考翻译中的次数,例如 the 在参考 1 中出现 2 次,在参考 2 中出现 1 次,所以 the 这个单词的得分最多是 2,而这个句子所有单词都是 the,那么总得分还是 2,所以修正后的精确度变为 $\frac{2}{7}$ .
bigram(双词词组) Bleu score
假设翻译结果:
- The cat the cat on the mat.
找出句子所有双词词组:
| 在句子中出现次数 Count | 在任何一个参考翻译中出现的最大次数 Count_clip | |
|---|---|---|
| the cat | 2 | 1 |
| cat the | 1 | 0 |
| cat on | 1 | 1 |
| on the | 1 | 1 |
| the mat | 1 | 1 |
| 总和 | 6 | 4 |
最后的双词组精确度就是 $\frac{4}{6}$.
n-gram(n 词词组)的 Bleu score
- $P_n$ 指的是 n 词词组的 Bleu score
- 其中 $Count_{clip}$ 指的是某个词组在任何一个参考翻译中出现的最大次数,$Count$ 指的是某个词组在句子中出现的总次数
组合 Bleu score
- 其中 BP 指的是 brevity penalty 简短惩罚因子,如果输出非常简短的翻译,就很容易得到高精准度,因为可能大部分输出的字都在参考表里,但是我们不希望翻译是非常短的,因此,简短惩罚就是一个调整因素,用来惩罚翻译系统中输出的非常简短的翻译。
注意力模型 Attention Model
长序列翻译存在的问题
传统的机器翻译采用 编码器-解码器 的模型,先将输入语句全部读入编码器得到一个编码向量,然后再通过解码器进行输出。
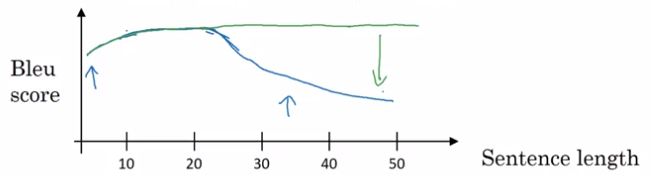
对于一个很长的句子而言,人类的翻译方式是先读一部分翻译一部分,再读一部分翻译一部分,模型采用的方式是先将整个句子进行读取再进行输出,但是模型无法记住特别长的句子,所以对于 编码器-解码器 翻译模型来说,模型的表现随着句子长度先增大后减小,如下图中的蓝线。而引入一种模拟人一段一段翻译的“注意力模型”,可以使得机器翻译系统的表现不随序列长度增大而减小,如下图绿线。
注意力模型 intuition
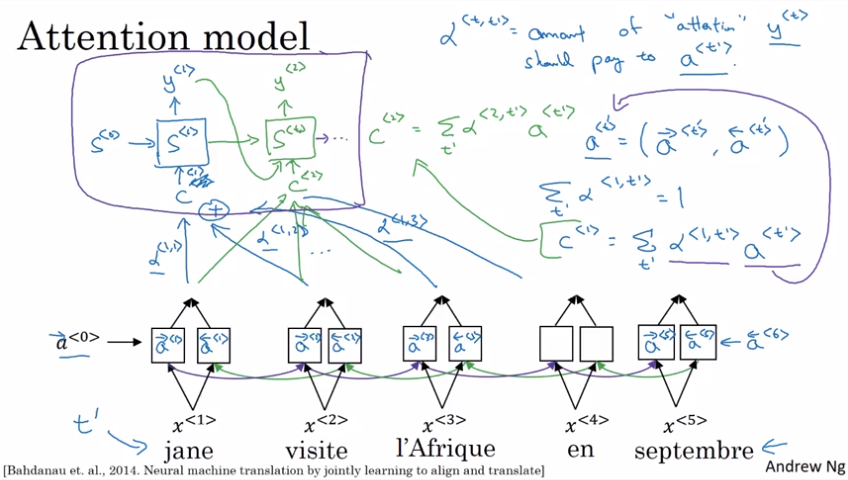
其中:
- $t’$ 为输入序列,$t$ 为输出序列
- $ \alpha ^ {< t , t’ >}$ 是注意力权重,表示 $y^{< t >}$ 应该放在 $a^{< t’ >}$ 上的“注意力”的多少,且 $\sum\limits_{t’} \alpha^{<t, t’ >}=1$
- $ c^{< t >}=\sum\limits_{t’} \alpha^{< t , t’ >}a ^ {< t’ >} $ 指的是整个上下文应该放在第 t 个输出的“注意力”
- $a^{< t’ >}=(\stackrel{\rightarrow}{a}^{< t’ >},\stackrel{\leftarrow}{a}^{< t’ >})$ 指双向 RNN 在 t‘ 时刻的激活值
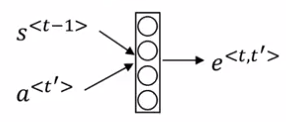
如何计算注意力权重
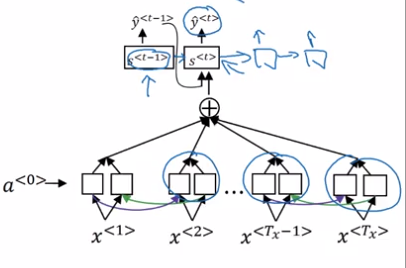
为了得到每个词的注意力权重,我们可以将 $s^{< t -1 >}$ 和所有的激活值 $a^{< t’ >}$ 输入一个只有一层的小型神经网络,得到 $e ^ {< t , t’ >}$,那么 $\alpha ^ {< t , t’ >}$ 就是 $e ^ {< t , t’ >}$ 的 softmax 值,然后交给模型自己去训练。
这个算法的一个问题是需要二次时间成本。
注意力模型的例子
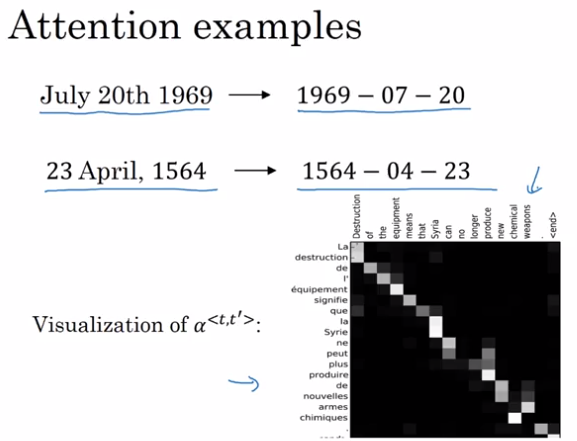
上图是注意力权重的可视化,我们可以看到机器翻译输入和输出对应的词语具有很高的注意力权重。
语音识别
语音识别问题
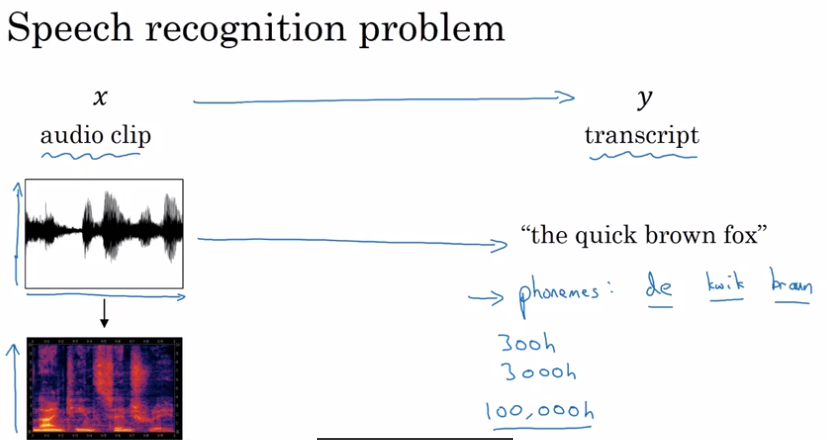
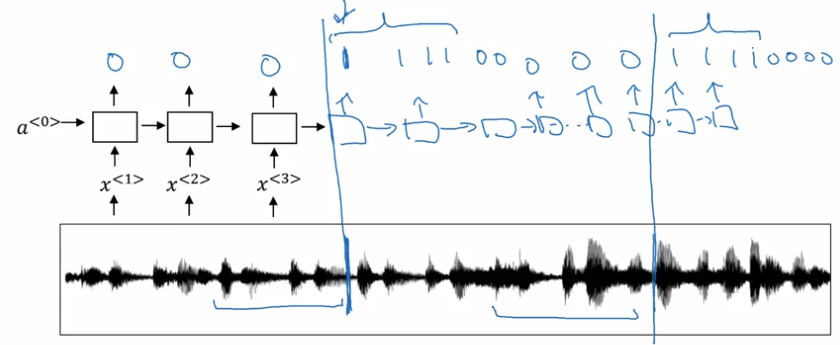
以前语音识别系统基于“音素”,例如”The”有一个”de”音 “e”音,”Quick”有一个”ku”音 “u”音 “ik”音 “k”音,语言学家假设音素是声音的基本单元。然而,用端到端的深度学习,我们发现用音素表示声音不再是必要的,你可以开发一个系统,,输入一个音频片段,并直接输出文字,而不需要使用像这样的手工设计的表示方法。更大的数据集使这成为可能,很多学术论文,是基于上千个小时的数据集的,最好的商业性的系统是在超过 1 万甚至 10 万小时的音频数据集上训练的。标注的声频数据集,和深度学习算法极大地推动语音识别地进步。
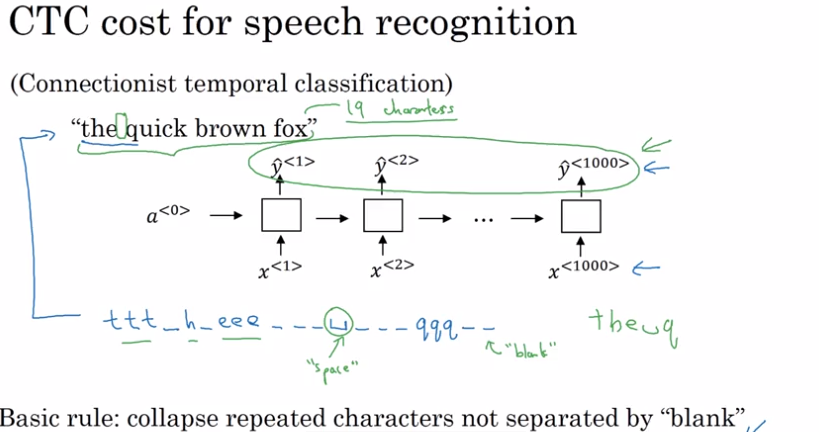
语音识别的 CTC(联结主义时间分类) 损失函数
由于语音识别一般输入远远大于输出,如何定义损失函数?CTC 损失函数允许 RNN 生成这样的输出序列:“ttt_h_eee_ _ _ <空格 > _ _ _ qqq _ _” ,其中 _ 指空白字符,基本原则是:允许折叠那些没有被空白字符隔开的重复字符。所以上述输出变为“the q”。所以例如“the quick brown fox.” 这种短句子,我们可以往其中插入空白字符 _ 和字母重复来扩充到需要的长度。
触发词 (激活词) 检测系统
什么是触发词检测系统?
用 Alexa 这个词唤醒亚马逊的 echo, 用“小度你好”唤醒的百度的 BaiduDuerOS,用 Hey Siri 唤醒苹果的 Siri 智能语音助手,用 ok Google 来唤醒 Google Home.

将训练语音输入模型,标签设置为触发词对应的时间点为 1 (为了保持 0 和 1 的平衡,可以令触发词后的一段时间都为 1),然后进行训练。