defread_glove_vecs(glove_file): with open(glove_file, 'r') as f: words = set() word_to_vec_map = {} for line in f: line = line.strip().split() curr_word = line[0] words.add(curr_word) word_to_vec_map[curr_word] = np.array(line[1:], dtype=np.float64) return words, word_to_vec_map
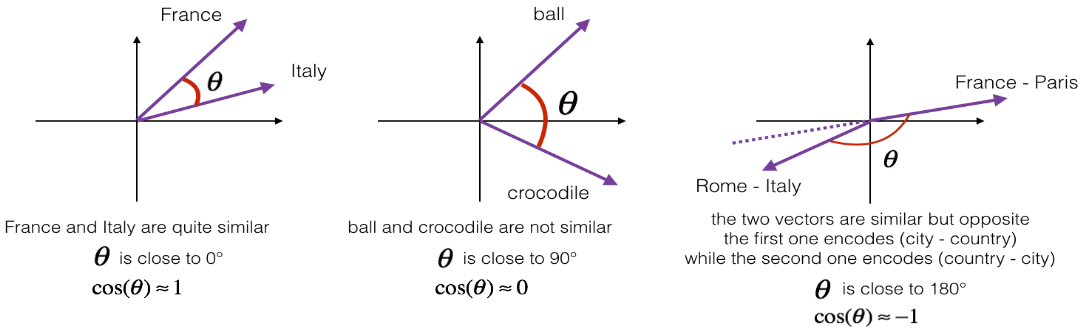
defcosine_similarity(u, v): """ Cosine similarity reflects the degree of similariy between u and v Arguments: u -- a word vector of shape (n,) v -- a word vector of shape (n,) Returns: cosine_similarity -- the cosine similarity between u and v defined by the formula above. """ distance = 0.0 # Compute the dot product between u and v (≈1 line) dot = np.dot(u,v) # Compute the L2 norm of u (≈1 line) norm_u = np.sqrt(np.sum(np.square(u))) # Compute the L2 norm of v (≈1 line) norm_v = np.sqrt(np.sum(np.square(v))) # Compute the cosine similarity defined by formula (1) (≈1 line) cosine_similarity = dot/(norm_u*norm_v)
return cosine_similarity
词语类比
要实现 “a is to b as c is to __“ 这种类比任务,我们可以从词向量词汇表里面找出这么一个词使得 $e_b - e_a \approx e_d - e_c$
defcomplete_analogy(word_a, word_b, word_c, word_to_vec_map): """ Performs the word analogy task as explained above: a is to b as c is to ____. Arguments: word_a -- a word, string word_b -- a word, string word_c -- a word, string word_to_vec_map -- dictionary that maps words to their corresponding vectors. Returns: best_word -- the word such that v_b - v_a is close to v_best_word - v_c, as measured by cosine similarity """ # convert words to lower case word_a, word_b, word_c = word_a.lower(), word_b.lower(), word_c.lower() # Get the word embeddings v_a, v_b and v_c (≈1-3 lines) e_a, e_b, e_c = word_to_vec_map[word_a], word_to_vec_map[word_b], word_to_vec_map[word_c] words = word_to_vec_map.keys() max_cosine_sim = -100# Initialize max_cosine_sim to a large negative number best_word = None# Initialize best_word with None, it will help keep track of the word to output
# loop over the whole word vector set for w in words: # to avoid best_word being one of the input words, pass on them. if w in [word_a, word_b, word_c] : continue # Compute cosine similarity between the vector (e_b - e_a) and the vector ((w's vector representation) - e_c) (≈1 line) cosine_sim = cosine_similarity(word_to_vec_map[w], e_b-e_a+e_c)#找出使得这个值最小的 # If the cosine_sim is more than the max_cosine_sim seen so far, # then: set the new max_cosine_sim to the current cosine_sim and the best_word to the current word (≈3 lines) if cosine_sim > max_cosine_sim: max_cosine_sim = cosine_sim best_word = w return best_word
g = word_to_vec_map['woman'] - word_to_vec_map['man']
现在看看男生女生的名字和偏见轴的相似度:
1 2 3 4 5 6 7
print ('List of names and their similarities with constructed vector:')
# girls and boys name name_list = ['john', 'marie', 'sophie', 'ronaldo', 'priya', 'rahul', 'danielle', 'reza', 'katy', 'yasmin','bill']
for w in name_list: print (w, cosine_similarity(word_to_vec_map[w], g))
List of names and their similarities with constructed vector: john -0.23163356146 marie 0.315597935396 sophie 0.318687898594 ronaldo -0.312447968503 priya 0.17632041839 rahul -0.169154710392 danielle 0.243932992163 reza -0.079304296722 katy 0.283106865957 yasmin 0.233138577679 bill -0.0306830313755
print('Other words and their similarities:') word_list = ['lipstick', 'guns', 'science', 'arts', 'literature', 'warrior','doctor', 'tree', 'receptionist', 'technology', 'fashion', 'teacher', 'engineer', 'pilot', 'computer', 'singer'] for w in word_list: print (w, cosine_similarity(word_to_vec_map[w], g))
Other words and their similarities: lipstick 0.276919162564 guns -0.18884855679 science -0.0608290654093 arts 0.00818931238588 literature 0.0647250443346 warrior -0.209201646411 doctor 0.118952894109 tree -0.0708939917548 receptionist 0.330779417506 technology -0.131937324476 fashion 0.0356389462577 teacher 0.179209234318 engineer -0.0803928049452 pilot 0.00107644989919 computer -0.103303588739 singer 0.185005181365
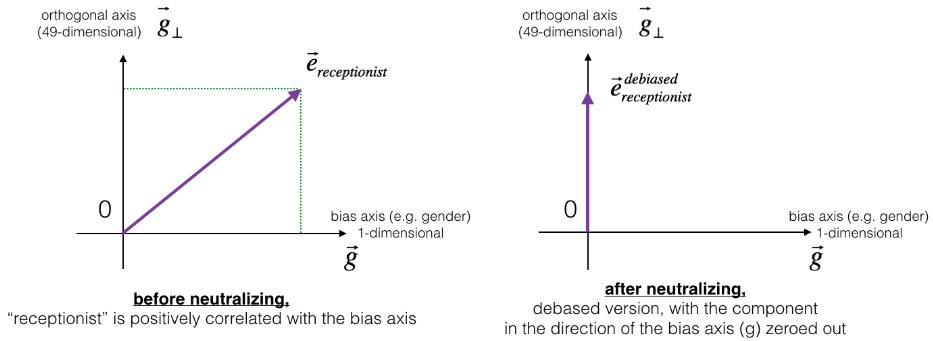
defneutralize(word, g, word_to_vec_map): """ Removes the bias of "word" by projecting it on the space orthogonal to the bias axis. This function ensures that gender neutral words are zero in the gender subspace. Arguments: word -- string indicating the word to debias g -- numpy-array of shape (50,), corresponding to the bias axis (such as gender) word_to_vec_map -- dictionary mapping words to their corresponding vectors. Returns: e_debiased -- neutralized word vector representation of the input "word" """
# Select word vector representation of "word". Use word_to_vec_map. (≈ 1 line) e = word_to_vec_map[word] # Compute e_biascomponent using the formula give above. (≈ 1 line) e_biascomponent = (np.dot(e,g)/np.linalg.norm(g)**2) * g # Neutralize e by substracting e_biascomponent from it # e_debiased should be equal to its orthogonal projection. (≈ 1 line) e_debiased = e - e_biascomponent return e_debiased
我们看看“接待员”这个词在中立化前后中立化后与偏差轴的相似度:
1 2 3 4 5
e = "receptionist" print("cosine similarity between " + e + " and g, before neutralizing: ", cosine_similarity(word_to_vec_map["receptionist"], g))
e_debiased = neutralize("receptionist", g, word_to_vec_map) print("cosine similarity between " + e + " and g, after neutralizing: ", cosine_similarity(e_debiased, g))
cosine similarity between receptionist and g, before neutralizing: 0.330779417506 cosine similarity between receptionist and g, after neutralizing: -3.26732746085e-17
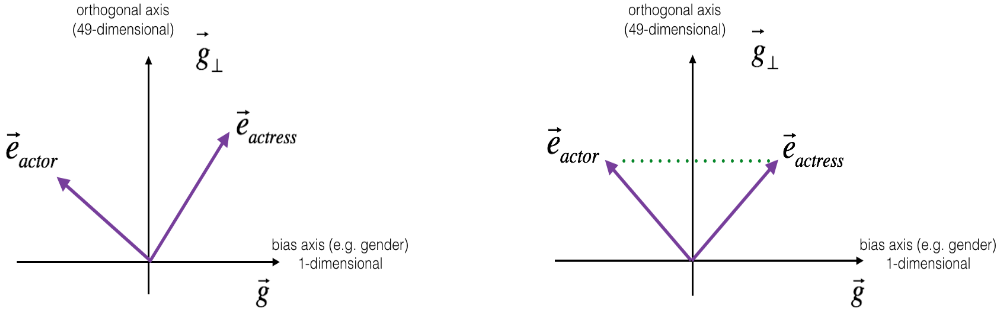
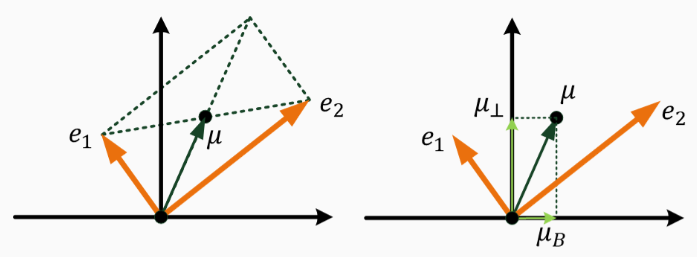
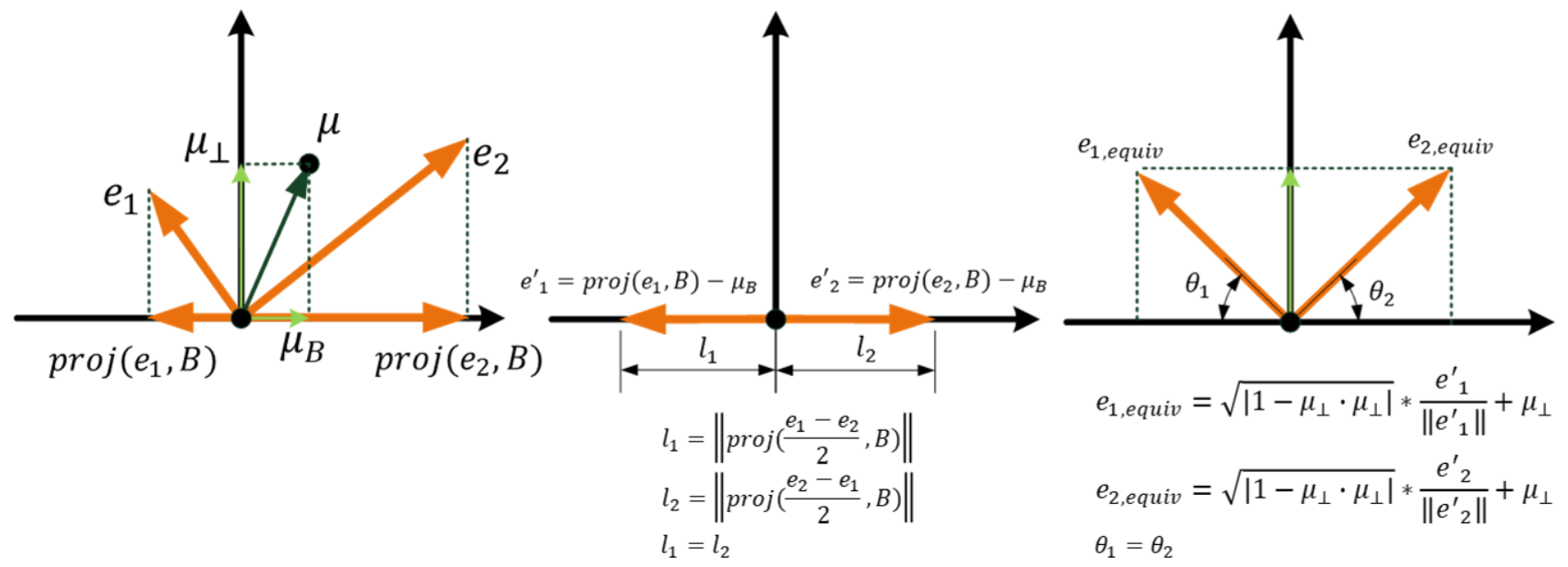
平均化 Equalization algorithm for gender-specific words
defequalize(pair, bias_axis, word_to_vec_map): """ Debias gender specific words by following the equalize method described in the figure above. Arguments: pair -- pair of strings of gender specific words to debias, e.g. ("actress", "actor") bias_axis -- numpy-array of shape (50,), vector corresponding to the bias axis, e.g. gender word_to_vec_map -- dictionary mapping words to their corresponding vectors Returns e_1 -- word vector corresponding to the first word e_2 -- word vector corresponding to the second word """ # Step 1: Select word vector representation of "word". Use word_to_vec_map. (≈ 2 lines) w1, w2 = pair e_w1, e_w2 = word_to_vec_map[w1],word_to_vec_map[w2] # Step 2: Compute the mean of e_w1 and e_w2 (≈ 1 line) mu = (e_w1 + e_w2)/2
# Step 3: Compute the projections of mu over the bias axis and the orthogonal axis (≈ 2 lines) mu_B = (np.dot(mu,bias_axis)/(np.linalg.norm(bias_axis)**2)) * bias_axis mu_orth = mu - mu_B
# Step 4: Use equations (7) and (8) to compute e_w1B and e_w2B (≈2 lines) e_w1B = (np.dot(e_w1,bias_axis)/(np.linalg.norm(bias_axis)**2)) * bias_axis e_w2B = (np.dot(e_w2,bias_axis)/(np.linalg.norm(bias_axis)**2)) * bias_axis # Step 5: Adjust the Bias part of e_w1B and e_w2B using the formulas (9) and (10) given above (≈2 lines) corrected_e_w1B = np.sqrt(abs(1-np.linalg.norm(mu_orth)**2)) * ((e_w1B-mu_B)/np.linalg.norm(e_w1B-mu_B)) corrected_e_w2B = np.sqrt(abs(1-np.linalg.norm(mu_orth)**2)) * ((e_w2B-mu_B)/np.linalg.norm(e_w2B-mu_B))
# Step 6: Debias by equalizing e1 and e2 to the sum of their corrected projections (≈2 lines) e1 = corrected_e_w1B + mu_orth e2 = corrected_e_w2B + mu_orth return e1, e2
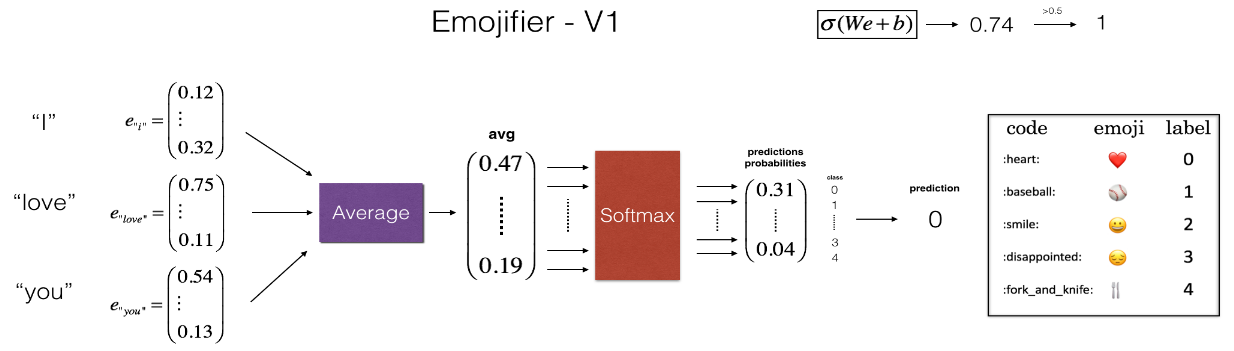
defsentence_to_avg(sentence, word_to_vec_map): """ Converts a sentence (string) into a list of words (strings). Extracts the GloVe representation of each word and averages its value into a single vector encoding the meaning of the sentence. Arguments: sentence -- string, one training example from X word_to_vec_map -- dictionary mapping every word in a vocabulary into its 50-dimensional vector representation Returns: avg -- average vector encoding information about the sentence, numpy-array of shape (50,) """ # Step 1: Split sentence into list of lower case words (≈ 1 line) words = sentence.lower().split()
# Initialize the average word vector, should have the same shape as your word vectors. avg = np.zeros((50,)) # Step 2: average the word vectors. You can loop over the words in the list "words". for w in words: avg += word_to_vec_map[w] avg = avg / len(words)
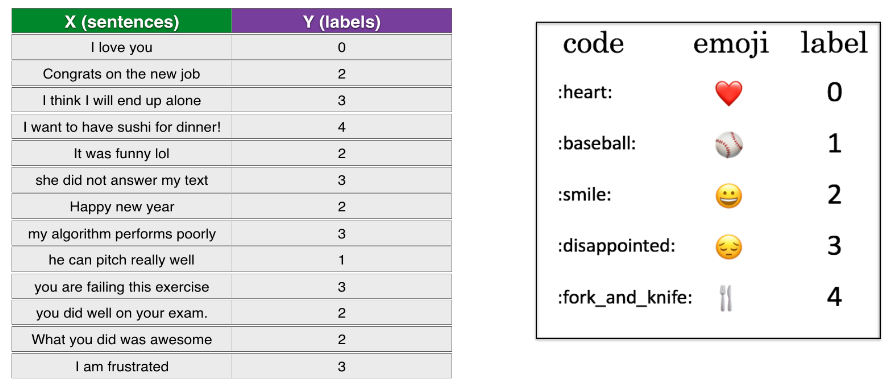
defmodel(X, Y, word_to_vec_map, learning_rate = 0.01, num_iterations = 400): """ Model to train word vector representations in numpy. Arguments: X -- input data, numpy array of sentences as strings, of shape (m, 1) Y -- labels, numpy array of integers between 0 and 7, numpy-array of shape (m, 1) word_to_vec_map -- dictionary mapping every word in a vocabulary into its 50-dimensional vector representation learning_rate -- learning_rate for the stochastic gradient descent algorithm num_iterations -- number of iterations Returns: pred -- vector of predictions, numpy-array of shape (m, 1) W -- weight matrix of the softmax layer, of shape (n_y, n_h) b -- bias of the softmax layer, of shape (n_y,) """ np.random.seed(1)
# Define number of training examples m = Y.shape[0] # number of training examples n_y = 5# number of classes n_h = 50# dimensions of the GloVe vectors # Initialize parameters using Xavier initialization W = np.random.randn(n_y, n_h) / np.sqrt(n_h) b = np.zeros((n_y,)) # Convert Y to Y_onehot with n_y classes Y_oh = convert_to_one_hot(Y, C = n_y) # Optimization loop for t in range(num_iterations): # 遍历完所有的 epoch for i in range(m): # 每一个 epoch 遍历完所有样本,每一个样本更新一次参数,应该是随机梯度下降 # Average the word vectors of the words from the i'th training example avg = sentence_to_avg(X[i], word_to_vec_map)
# Forward propagate the avg through the softmax layer z = np.dot(W,avg)+b a = softmax(z)
# Compute cost using the i'th training label's one hot representation and "A" (the output of the softmax) cost = -np.sum(Y_oh*np.log(a)) # Compute gradients dz = a - Y_oh[i] dW = np.dot(dz.reshape(n_y,1), avg.reshape(1, n_h)) db = dz
# Update parameters with Stochastic Gradient Descent W = W - learning_rate * dW b = b - learning_rate * db if t % 100 == 0: print("Epoch: " + str(t) + " --- cost = " + str(cost)) pred = predict(X, Y, W, b, word_to_vec_map)
return pred, W, b
训练模型:
1 2
pred, W, b = model(X_train, Y_train, word_to_vec_map) print(pred)
Training set: Accuracy: 0.977272727273 Test set: Accuracy: 0.857142857143
自己随便写几个句子进行测试:
1 2 3 4 5
X_my_sentences = np.array(["i hate you", "i love you", "funny lol", "lets play with a ball", "food is ready", "not feeling happy"]) Y_my_labels = np.array([[0], [0], [2], [1], [4],[3]])
pred = predict(X_my_sentences, Y_my_labels , W, b, word_to_vec_map) print_predictions(X_my_sentences, pred)
Accuracy: 0.666666666667
i hate you 😞 i love you ❤️ funny lol 😄 lets play with a ball ⚾ food is ready 🍴 not feeling happy 😄
这个模型没有考虑词语的前后联系,所以会出现 not feeling happy 😄 这种错误,接下来用 LSTM 模型来实现这个任务。
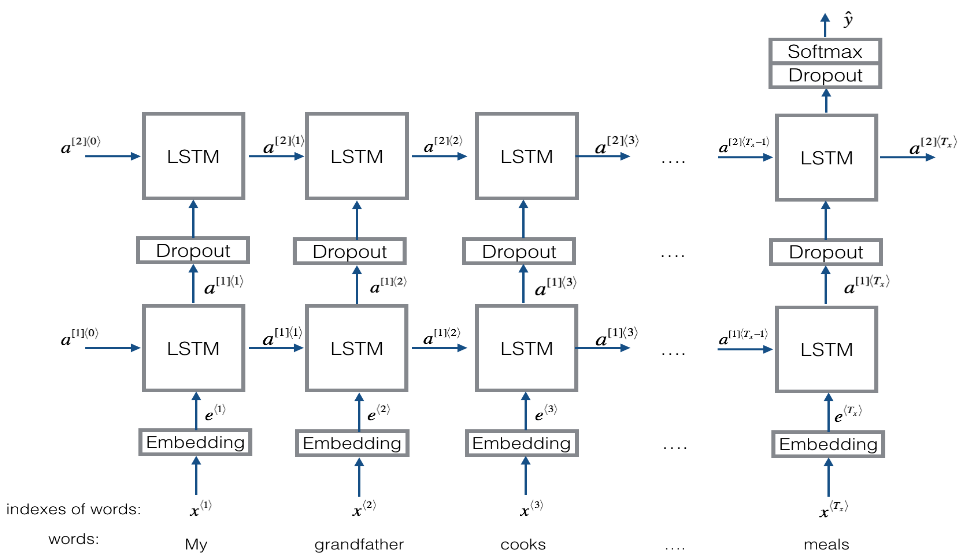
版本 2 - 在 Keras 中使用 LSTM 模型
1 2 3 4 5 6 7 8
import numpy as np np.random.seed(0) from keras.models import Model from keras.layers import Dense, Input, Dropout, LSTM, Activation from keras.layers.embeddings import Embedding from keras.preprocessing import sequence from keras.initializers import glorot_uniform np.random.seed(1)
模型概况
Keras 和 minibatch
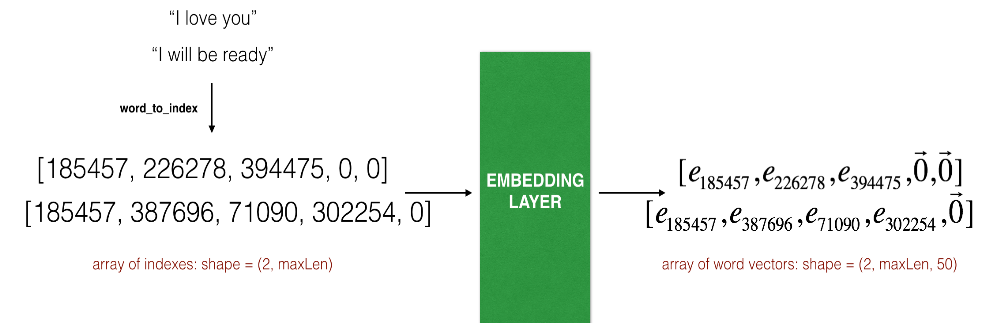
数据集中所有的句子长度不是统一的,而在 Keras 中要实现小批量梯度下降,某个 minibatch 中所有句子的长度必须全部相同,这样才能输入 LSTM 层进行训练,为了解决这个问题,我们可以将句子进行填充,以最长的句子为基准,不足的部分用零向量进行填充,假设最长的句子有 20 个词,那么 “I love you” 这个句子的词向量为 $(e_{i}, e_{love}, e_{you}, \vec{0}, \vec{0}, \ldots, \vec{0})$.
嵌入层
在 Keras 中,嵌入矩阵是用类似于嵌入层的形式实现的,输入一个由索引值组成的句子,输出句子每个词的词向量。接下来我们会实现一个用预训练词向量初始化过的嵌入层,由于训练集较小,保持嵌入层参数固定不被训练。
defsentences_to_indices(X, word_to_index, max_len): """ Converts an array of sentences (strings) into an array of indices corresponding to words in the sentences. The output shape should be such that it can be given to `Embedding()` (described in Figure 4). Arguments: X -- array of sentences (strings), of shape (m, 1) word_to_index -- a dictionary containing the each word mapped to its index max_len -- maximum number of words in a sentence. You can assume every sentence in X is no longer than this. Returns: X_indices -- array of indices corresponding to words in the sentences from X, of shape (m, max_len) """ m = X.shape[0] # number of training examples
# Initialize X_indices as a numpy matrix of zeros and the correct shape (≈ 1 line) X_indices = np.zeros((m,max_len)) # 这一步其实已经做好了零填充 for i in range(m): # loop over training examples # Convert the ith training sentence in lower case and split is into words. You should get a list of words. sentence_words = X[i].lower().split() # Initialize j to 0 j = 0 # Loop over the words of sentence_words for w in sentence_words: # Set the (i,j)th entry of X_indices to the index of the correct word. X_indices[i, j] = word_to_index[w] # Increment j to j + 1 j = j + 1 return X_indices
defpretrained_embedding_layer(word_to_vec_map, word_to_index): """ Creates a Keras Embedding() layer and loads in pre-trained GloVe 50-dimensional vectors. Arguments: word_to_vec_map -- dictionary mapping words to their GloVe vector representation. word_to_index -- dictionary mapping from words to their indices in the vocabulary (400,001 words) Returns: embedding_layer -- pretrained layer Keras instance """ # 以下部分都是为了将我们自己的词嵌入矩阵变成 Embedding 层的参数要求的形状 vocab_len = len(word_to_index) + 1# Keras embedding 层输入的规定,估计是注意词汇表的索引值第一个是 1 而不是 0,所以要加一 emb_dim = word_to_vec_map["cucumber"].shape[0] # define dimensionality of your GloVe word vectors (= 50)
# 先用 0 初始化一个正确的形状(vocab_len,emb_dim)的矩阵 emb_matrix = np.zeros((vocab_len, emb_dim))# 这个是传入Keras embedding 层的参数,它的形状必须跟 embedding.get_weights() 的形状相同 # 按照索引值将正确的词向量填入这个矩阵 for word, index in word_to_index.items(): emb_matrix[index, :] = word_to_vec_map[word] # 从这里开始构建 Keras 的 embedding 层 # Define Keras embedding layer with the correct output/input sizes, make it trainable. Use Embedding(...). Make sure to set trainable=False. embedding_layer = Embedding(vocab_len,emb_dim,trainable=False)# 这个将该层调为“不可训练”,保持其参数不变 # Build the embedding layer, it is required before setting the weights of the embedding layer. Do not modify the "None". embedding_layer.build((None,))# 这里不太懂?? # 将该层的参数设为我们自己的词嵌入矩阵 embedding_layer.set_weights([emb_matrix]) return embedding_layer
defEmojify_V2(input_shape, word_to_vec_map, word_to_index): """ Function creating the Emojify-v2 model's graph. Arguments: input_shape -- shape of the input, usually (max_len,) word_to_vec_map -- dictionary mapping every word in a vocabulary into its 50-dimensional vector representation word_to_index -- dictionary mapping from words to their indices in the vocabulary (400,001 words) Returns: model -- a model instance in Keras """
# 定义输入层 sentence_indices = Input(shape=input_shape, dtype='int32') # 创建嵌入层(参数是自己训练好的词嵌入矩阵) embedding_layer = pretrained_embedding_layer(word_to_vec_map, word_to_index) # 将输入向前传播 embeddings = embedding_layer(sentence_indices) # 继续传播经过一个隐藏单元数为 128 的 LSTM 层 X = LSTM(units=128, return_sequences=True)(embeddings)# 注意设置 return_sequences=True,返回所有时间序列 # 继续经过一个概率值为 0.5 的 Dropout 层 X = Dropout(0.5)(X) # 继续传播经过一个隐藏单元数为 128 的 LSTM 层 X = LSTM(units=128)(X)# 注意不用设置 return_sequences=True,默认返回最后一个cell的值 # 继续经过一个概率值为 0.5 的 Dropout 层 X = Dropout(0.5)(X) # 这是 softmax 层的第一部分,先通过一个全连接层 X = Dense(5)(X) # 再通过 softmax 激活函数层 X = Activation('softmax')(X) # 创建从 sentence_indices 到 X 的模型 model = Model(input=sentence_indices, outputs=X) return model
让我们看看模型的 summary,maxLen 为 10:
1 2
model = Emojify_V2((maxLen,), word_to_vec_map, word_to_index) model.summary()
32/56 [================>………….] - ETA: 0s Test accuracy = 0.821428562914
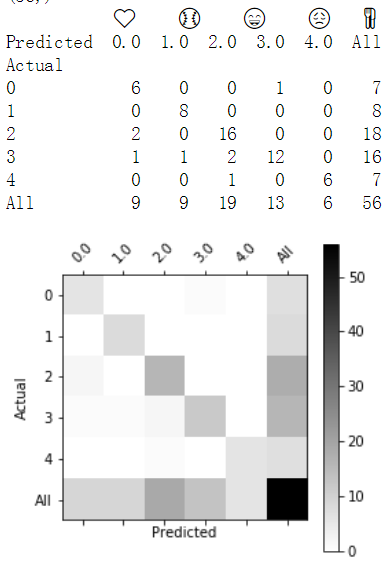
结果还不错!接下来看看哪些地方搞错了!
1 2 3 4 5 6 7 8 9 10
C = 5 y_test_oh = np.eye(C)[Y_test.reshape(-1)] # np.eye(C)生成5×5的对角矩阵,np.eye(C)[Y_test.reshape(-1)]取[]中每个元素的索引值 # 注意 np.array[np.array] 将会把 [] 中所有的元素索引出来 X_test_indices = sentences_to_indices(X_test, word_to_index, maxLen) pred = model.predict(X_test_indices) for i in range(len(X_test)): x = X_test_indices num = np.argmax(pred[i])# 将 onehot 变成索引 if(num != Y_test[i]): print('Expected emoji:'+ label_to_emoji(Y_test[i]) + ' prediction: '+ X_test[i] + label_to_emoji(num).strip())
Expected emoji:😄 prediction: she got me a nice present ❤️ Expected emoji:😞 prediction: work is hard 😄 Expected emoji:😞 prediction: This girl is messing with me ❤️ Expected emoji:😞 prediction: work is horrible 😄 Expected emoji:🍴 prediction: any suggestions for dinner 😄 Expected emoji:😄 prediction: you brighten my day ❤️ Expected emoji:😞 prediction: she is a bully 😄 Expected emoji:😞 prediction: My life is so boring ❤️ Expected emoji:😄 prediction: will you be my valentine ❤️ Expected emoji:😞 prediction: go away ⚾ Expected emoji:🍴 prediction: I did not have breakfast ❤️