自然语言处理和深度学习是非常重要的组合。使用词向量表示和嵌入层可以在许多行业训练 RNN,例如情感分析,命名实体识别和机器翻译。
Word Embeddings 词嵌入介绍
Word representation
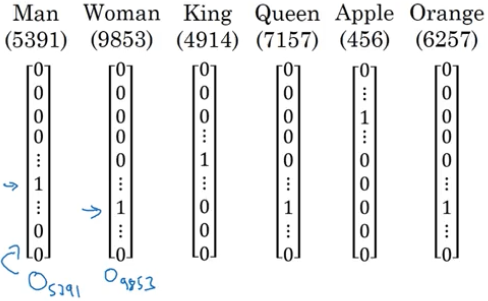
如何用向量表示一个词?假设我们有一个词汇表 V,数量为 |V| = 10000,V = {a, aaron,…, zulu,<UNK>},我们可以用 one-hot 编码来表示这些词:
但是问题是,对于这两个句子:
- I want a glass of orange ____.
- I want a glass of apple ____.
对于算法来说,orange juice 是一个非常可能的选择,那么对于 apple 来说,apple juice 也是一个很可能的选择,但是由于 one-hot 编码没能体现出 orange 和 apple 的密切关系(都是水果),所以在这里单词 king 和 orange 的相关程度并不比 apple 低。用词向量表示可以解决这个问题。
我们先创建一系列特征:性别 gender、皇室 royal、年龄 age、食物 food……用一个数字表示某个词跟这个特征的相关程度,然后形成一个特征向量。

于是,我们可以发现 apple 和 orange 具有更加接近的特征向量,在这一点上与实际情况更加符合。
将这些特征向量可视化,我们可以发现这些词是一组一组分布的。
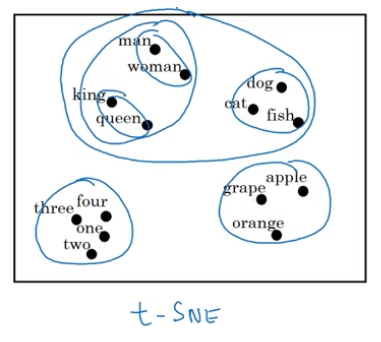
什么是词嵌入?假设特征向量的维度是三维,这形成一个三维的特征空间,每个词在这个空间中占据一个位置,就如同嵌入一样,所以我们称之为“词嵌入”。其实词嵌入相当于给词编码。
使用词嵌入
词嵌入对于迁移学习非常有用,即将具有很多数据集的任务 A 迁移到数据集较少的任务 B。
- 从大量的文本语料库(十亿到几千亿个单词)中学习单词嵌入,或者下载在线的训练好的词嵌入。
- 将这些词嵌入迁移学习到训练集更小的新任务上。(比如十万个词左右)
- 可选:继续使用新数据来微调词嵌入。如果第二步训练集太小,通常不会继续微调。
词嵌入的属性
我们可以用词向量来进行词的类比:
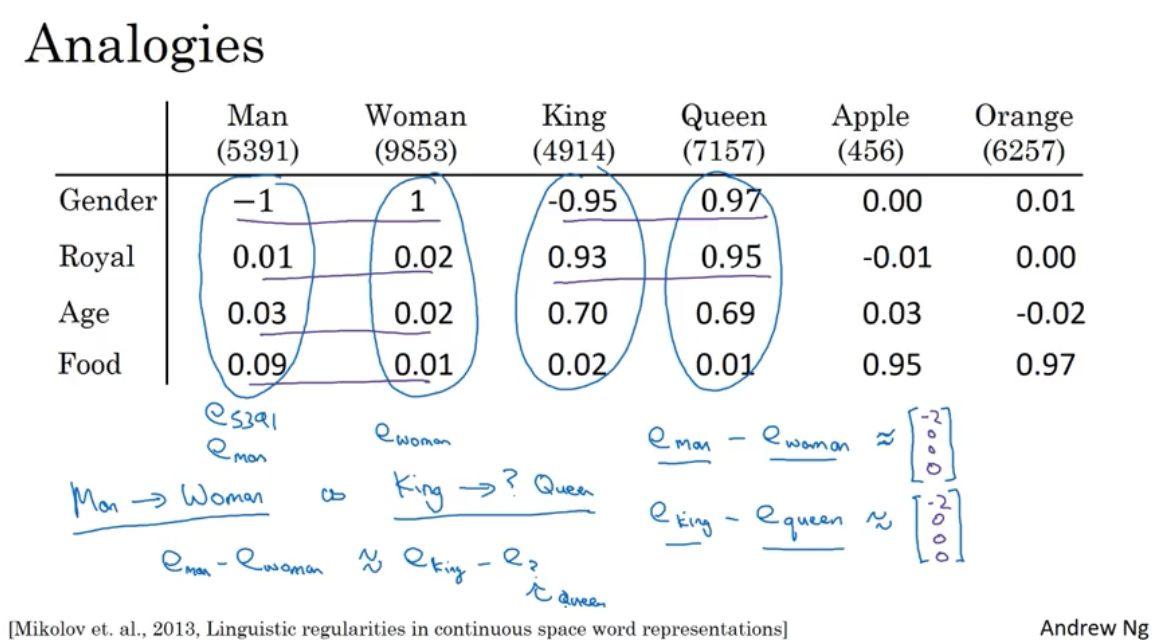
在词向量空间中,代表 man 的这个词的词向量和代表 woman 这个词的词向量之间的距离与 king 向量和 queen 向量之间的距离近似相等,如下图所示:
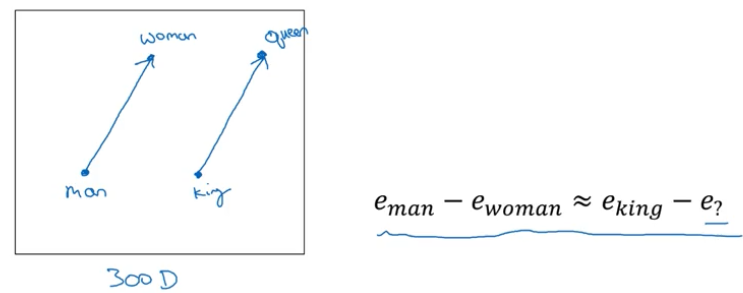
要找到和 man -> woman 类似的一对词 king -> ?,我们可以遍历所有词向量,找到这么一个词 w 满足:$sim(e_w,e_{king}-e_{man}+e_{woman})$ 最大,其中 sim() 是 “cosine 相似度”。
它其实表示的是向量 u 和 v 之间的 cos 值,cos 值越大表示两者夹角越小,相似度越大。
另外 $||u-v||^2$ 也可以表示两者的相似度。
嵌入矩阵 Embedding matrix
当实现一个算法来学习字嵌入时,最终学习到的是一个嵌入矩阵 E,这个矩阵乘上某个词(例如位于 6257 位的 orange )的 one-hot 向量($o_{6257}$)得到它的词向量($e_{6257}$),即:
其中 E 代表 Embedding 矩阵,o 代表 one-hot 向量,e 代表 embedding 向量。
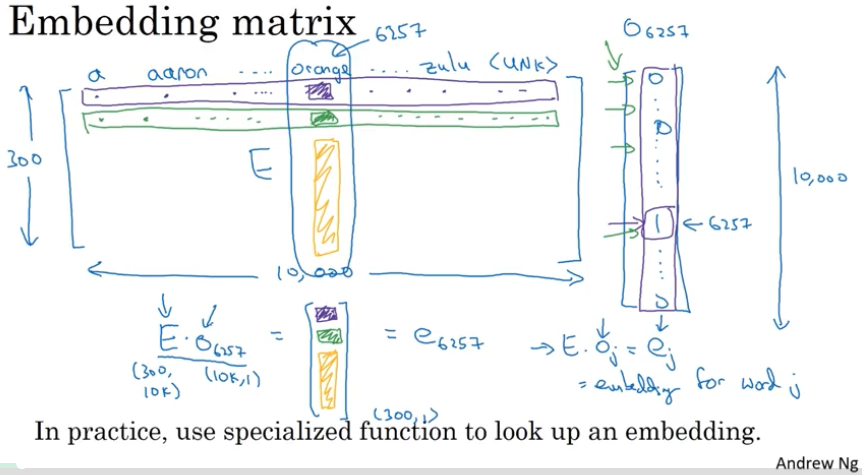
值得注意的是,实际中由于向量 o 大部分都是 0,所以不会真正地用 E 去对它进行矩阵乘法,而是使用特殊的函数进行查找。
学习词嵌入:Word2vec and Glove
“学习”词嵌入
如何通过算法学习得到词嵌入矩阵呢?
例如我们需要通过前面若干词预测最后一个词,I want a glass of orange ____. 我们先将前六个词的 one-hot 向量(10000 )乘上随机初始化的词嵌入矩阵 E,然后将得到的所有词向量 (300) 合并为一个向量 (1800),接着通过一层隐藏层,最后通过 softmax 输出一个 one-hot 向量 (10000),它就是我们的预测词。
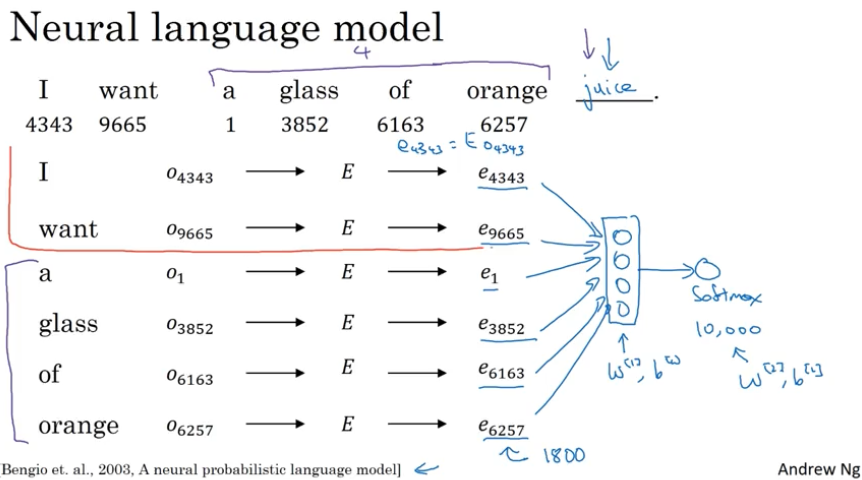
这个算法的一个超参数是选择固定窗的长度,上面是前六个词预测最后一个词,窗长就是六,也可以选择四个词的窗长,根据需要进行调整。
算法的参数就是 W 和 b 这些权值,使用它们进行梯度下降,使得训练集出现的可能性最大化。
这个算法为什么能学习到词嵌入?
如果训练集语料库中出现了 orange juice 和 apple juice,那么在这种样例的激励下,算法就会学习到 orange 和 apple 具有非常相似的词嵌入,这样才能更好地拟合训练集。
构造 上下文/目标词 组合
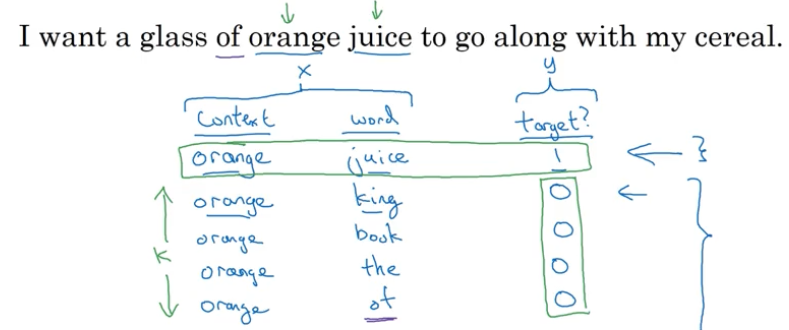
对于一句话 I want a glass of orange juice to go along with my cereal.
假如 juice 是我们需要预测的目标词,那么有许多种构造上下文来预测它的方法:
- 后面四个词
- 左边四个右边四个
- 最后一个词
- 附近一个词

Word2Vec
Skip-gram
下面是一种训练词向量的 skip-gram 模型,skip-gram 指的是我们先取一个词作为 context word,然后在固定窗的长度内的另一个词作为目标词 target word,然后我们就可以建立起一个监督学习问题了。如下图所示。

来自博客 seaboat 的一张图片: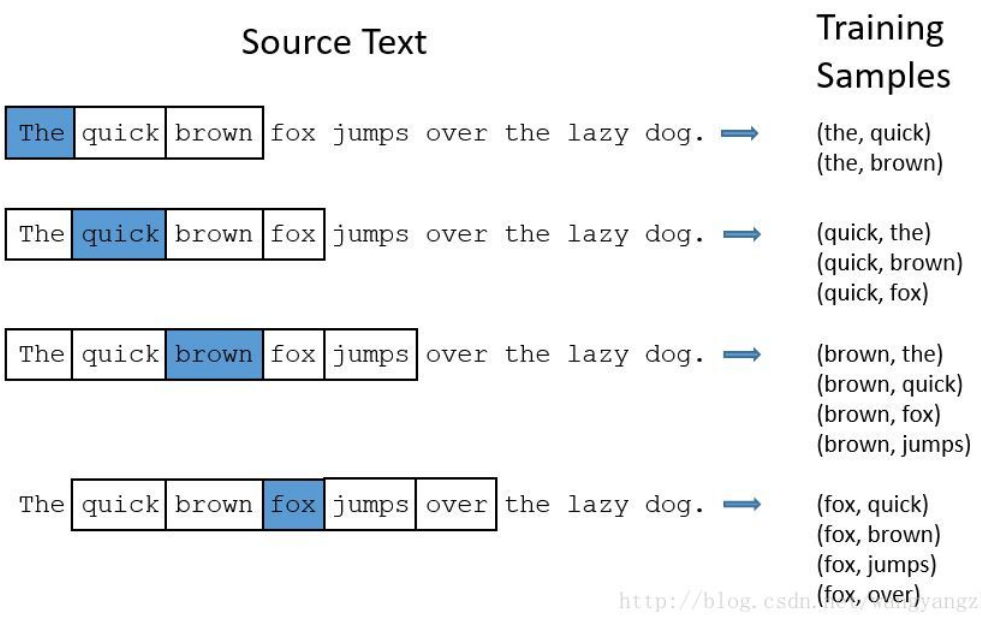
model details

$o_c \rightarrow 乘上E \rightarrow e_c \rightarrow softmax(W·e_c+b) \rightarrow \hat y$
其中 $W = \begin{bmatrix}
\theta_1^T\\
\theta_2^T\\
…\\
\theta_{10000}^T
\end{bmatrix}$
用 softmax 进行分类的问题
其中 $\theta_j$ 是 softmax 层的参数 W 的第 j 行,$\theta_t$ 是 W 中与输出有关的那一行。
softmax 层存在的问题是:我们需要进行 10000 次加法,这会非常非常慢!!解决的办法是使用一种“分级 softmax”分类器 (hierarchical softmax classifier)。
如何选择 context c
我们必须先选择好 context c,再在窗内随机选择 target t,那么如何选择 c?
一种办法是随机均匀地在文本中采样,但是问题是这样会采样进许多被频繁使用的词,比如 of the a an 等等,导致我们浪费时间在这些常用词的词嵌入上,所以我们需要在采样的时候适当地剔除这些词,实现常用词和不常用词的平衡。
负采样算法 negative sampling
首先定义一个新的监督学习问题,与上面 skip-gram 类似,先取一个词作为 context word,然后在固定窗的长度内随机挑选另一个词作为目标词 target word,如果选到了相关的词语例如 orange juice,那么这一个词语对的 y 值就是 1(正样本),否则就是 0(负样本),负样本的个数为 k.
如何选取 k?
- 对于小数据集:k = 5~20
- 对于大数据集:k = 2~5
算法细节
我们知道上面的 Word2Vec 算法步骤为:
$o_c \rightarrow E \rightarrow e_c \rightarrow softmax(W·e_c+b) \rightarrow one-hot向量\hat y$
其中 $W = \begin{bmatrix}\theta_1^T\\ \theta_2^T\\ …\\ \theta_{10000}^T\end{bmatrix},\hat y _t = p ( t | c ) = \frac { e ^ { \theta _ { t } ^ { T } e _ { c } } } { \sum _ { j = 1 } ^ { 10,000 } e ^ { \theta _ { j } ^ { T } e _ { c } } }$
而负采样算法去掉 softmax 的步骤,改为对 $e_c$ 进行 10000 次逻辑回归:
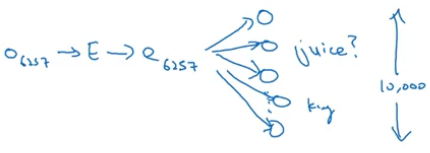
在实际中,我们只训练其中的 k+1 个逻辑回归模型,即训练 1 个正样本和 k 个负样本的逻辑回归模型,这样使得我们不用计算 10000 元分类的 softmax 层,大大减少计算量。
如何抽取负样本?
算法作者 Mikolov 认为,最好的方法是介于根据经验分布的采样和均匀分布的采样之间,他们所做的是根据词频的 3/4 次幂来抽样。
其中 $f^(w_i)$ 表示观察到的英语中某个词的词频。
GloVe 词向量 (global vector )
首先我们有一个目标词 i,还有一个上下文词 j,那么用 $X_{ij}$ 表示 i 出现在 j 的上下文的次数,一般来说,$X_{ij}=X_{ji}$ ,也就是说它表示 i 和 j 共同出现在一个上下文的次数,或者说彼此接近的频繁程度,可以遍历语料库数出来。
GloVe 算法就是实现以下的优化问题:
其中:
- 10000 是词汇表的个数,遍历整个词汇表
- $\theta、b_i、b’_j$ 都是待学习的参数
- 为了防止出现 $log0$ 无意义的情况,加上权重值 $f(x_{ij})$,当 $X_{ij}=0$ 时,$f(x_{ij})=0$,定义 $0log0=0$,另外权重函数可以使得对“榴莲”这种较少出现的词给出不太小的权重,给“of the an”等常见的词给出不太大的权重
- 一个有趣的事实是:$\theta_i $ 和 $e_j$ 是对称的,也就是说它们两者互为参数,起到的作用是相同的,所以我们最后学习到的参数可以是这两者的平均值,即 $e_w^{(final)}=\frac{e_w+\theta_w}{2}$
词嵌入的应用
情感分类
情感分类的任务是分析一段文本,告诉人们某个人是不是喜欢他们正在谈论的东西 。它是自然语言处理最重要的组成部分,有许多应用。情感分类的挑战之一是可能缺乏一个特别大的标签训练集,不过使用词嵌入后,依靠一个中等大小的标签训练集也可以构建出一个很好的情感分类器。
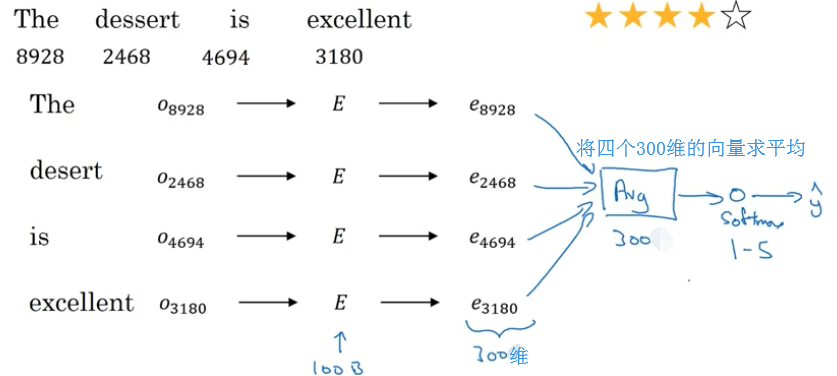
假设有一些顾客对一家酒店的评价和这些顾客打出的星级,如下图所示:

我们需要一个情感分类器,输入一段评价,然后猜出他给出的星级。
一个简单的情感分类模型
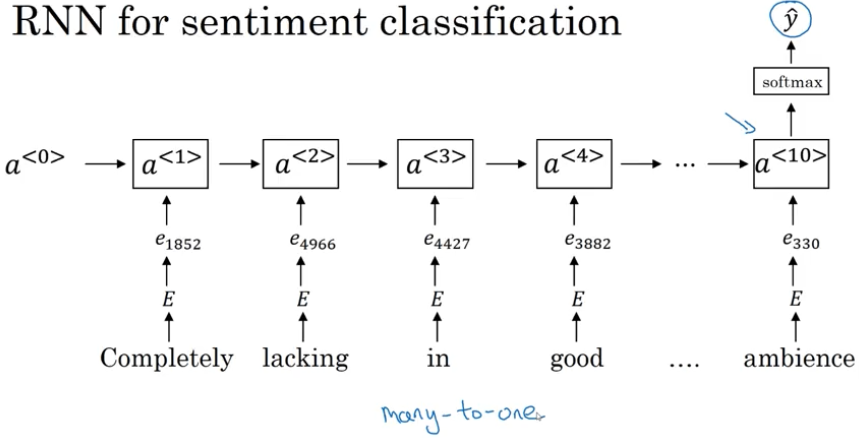
这个算法的一个问题是它忽视了词的顺序,和上下文的联系,例如“Completelylacking in good taste, good service, and good ambience” ,句子中出现了很多 good,但是实际上这是一个一星的差评,更好的方法是使用 RNN 进行情感分类。
用 RNN 进行情感分类
词嵌入“去偏见” Debiasing word embedding
由于词嵌入的训练语料是来自人类社会,而人类社会存在许多偏见,例如男人对应程序员,女人对应家庭主妇,而这是一个不正常的存在性别歧视的刻板印象。机器学习和 AI 算法越来越受人信任,可以用来帮人做出非常重要的决策,所以我们需要尽可能确保,算法中没有性别偏见、种族偏见等。一个不好的词嵌入会反应性别、种族、年龄和性取向,而比较好的算法应该能够得出:男人对应程序员而女人也对于程序员。这是非常具有人文主义的一项技术,展示了机器学习社群对减少社会偏见的责任感。
那么如何减小词嵌入中的“偏见”呢?
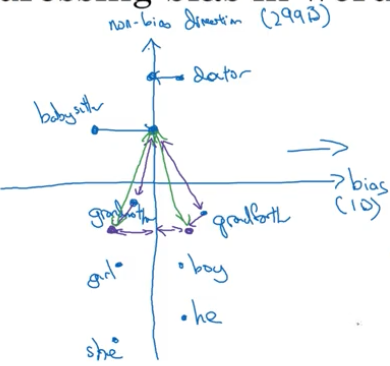
假设我们有一个训练好的词向量模型如下图所示:

第一步:确定偏差的方向
假设词向量中只有一个维度是表示性别偏差的方向,那么 $e_{he}-e_{she}$ 、$e_{male}-e_{female}$……然后将这些差值取平均,那么这个平均值向量就是表示偏差轴的向量,也就是偏差的方向。但是实际中使用了更复杂的 SVU 算法(一种类似于 PCA 主成份分析的算法)来确定偏差方向。
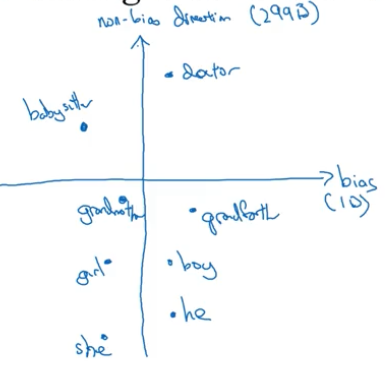
第二步是中立化(Neutralize):对于没有性别定义的词例如 doctor 或者 babysitter,通过将它们映射到非偏差轴摆脱偏差,如下图所示。那么那些词需要中立化?作者训练一个分类器来研究这个问题,得出的结论是大部分的英语单词都需要中立化,除了那些有性别定义的一小部分词语。
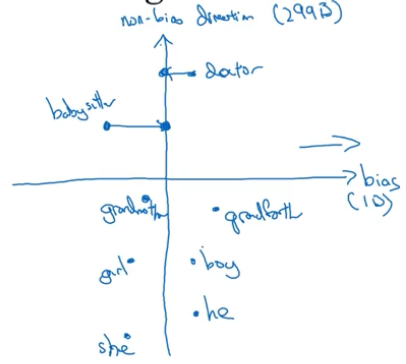
第三步是平均化(equalization):对于有性别定义的词例如 grandmother 和 grandfather 或者 boy 和 girl,我们希望这些词到非偏差轴的距离相同,即离修正后的 babysitter 这类词的距离相同,做法是移动 grandmother 和 grandfather 分别到一个点,使得到中间轴的距离相等。有许多这类词,grandmother-grandfather、 boy-girl、sorority-fraternity、girlhood-boyhood、sister-brother、niece-nephew、daughter-son 等等,这些都需要进行平均化。