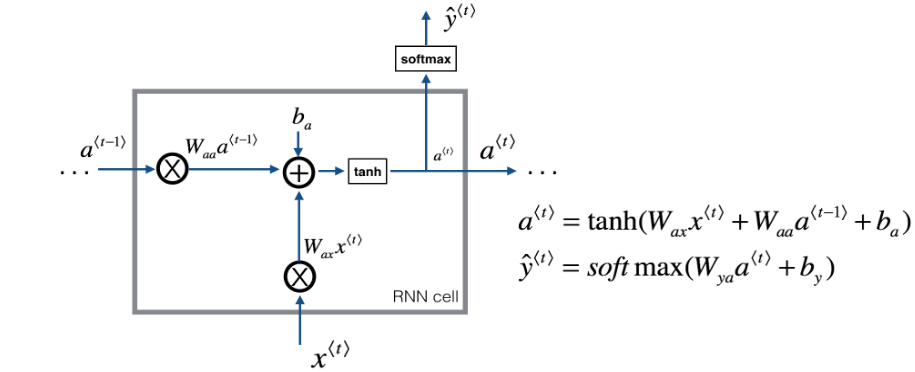
defrnn_cell_forward(xt, a_prev, parameters): """ Implements a single forward step of the RNN-cell as described in Figure (2) Arguments: xt -- your input data at timestep "t", numpy array of shape (n_x, m). a_prev -- Hidden state at timestep "t-1", numpy array of shape (n_a, m) parameters -- python dictionary containing: Wax -- Weight matrix multiplying the input, numpy array of shape (n_a, n_x) Waa -- Weight matrix multiplying the hidden state, numpy array of shape (n_a, n_a) Wya -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a) ba -- Bias, numpy array of shape (n_a, 1) by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1) Returns: a_next -- next hidden state, of shape (n_a, m) yt_pred -- prediction at timestep "t", numpy array of shape (n_y, m) cache -- tuple of values needed for the backward pass, contains (a_next, a_prev, xt, parameters) """ # Retrieve parameters from "parameters" Wax = parameters["Wax"] Waa = parameters["Waa"] Wya = parameters["Wya"] ba = parameters["ba"] by = parameters["by"]
# compute next activation state using the formula given above a_next = np.tanh(np.dot(Wax,xt) + np.dot(Waa,a_prev) + ba) # compute output of the current cell using the formula given above yt_pred = softmax(np.dot(Wya,a_prev) + by) # store values you need for backward propagation in cache cache = (a_next, a_prev, xt, parameters) return a_next, yt_pred, cache
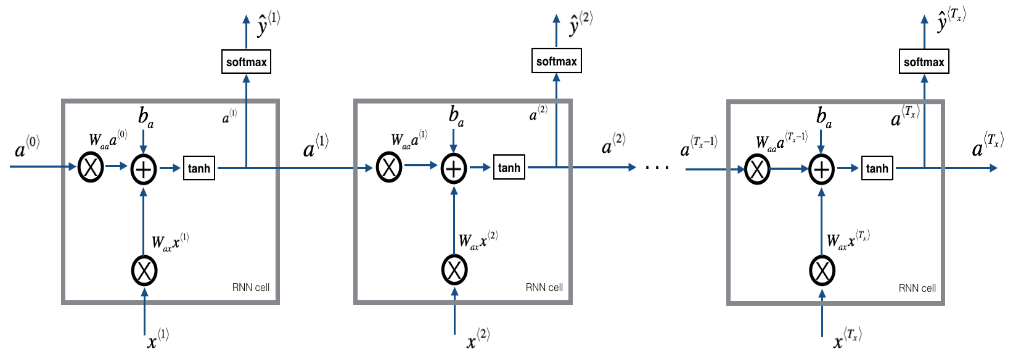
defrnn_forward(x, a0, parameters): """ Implement the forward propagation of the recurrent neural network described in Figure (3). Arguments: x -- Input data for every time-step, of shape (n_x, m, T_x). a0 -- Initial hidden state, of shape (n_a, m) parameters -- python dictionary containing: Waa -- Weight matrix multiplying the hidden state, numpy array of shape (n_a, n_a) Wax -- Weight matrix multiplying the input, numpy array of shape (n_a, n_x) Wya -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a) ba -- Bias numpy array of shape (n_a, 1) by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1) Returns: a -- Hidden states for every time-step, numpy array of shape (n_a, m, T_x) y_pred -- Predictions for every time-step, numpy array of shape (n_y, m, T_x) caches -- tuple of values needed for the backward pass, contains (list of caches, x) """ # Initialize "caches" which will contain the list of all caches caches = [] # Retrieve dimensions from shapes of x and parameters["Wya"] n_x, m, T_x = x.shape n_y, n_a = parameters["Wya"].shape # initialize "a" and "y" with zeros a = np.zeros((n_a,m,T_x)) # 初始化一个存放所有激活值的容器 y_pred = np.zeros((n_y,m,T_x)) # 初始化一个存放所有y预测值的容器 # Initialize a_next a_next = a0 # 将 a_next 初始化为 a<0> # loop over all time-steps for t in range(T_x): # Update next hidden state, compute the prediction, get the cache (≈1 line) a_next, yt_pred, cache = rnn_cell_forward(x[:,:,t], a_next, parameters) # Save the value of the new "next" hidden state in a (≈1 line) a[:,:,t] = a_next # Save the value of the prediction in y (≈1 line) y_pred[:,:,t] = yt_pred # Append "cache" to "caches" (≈1 line) caches.append(cache)
# store values needed for backward propagation in cache caches = (caches, x) return a, y_pred, caches
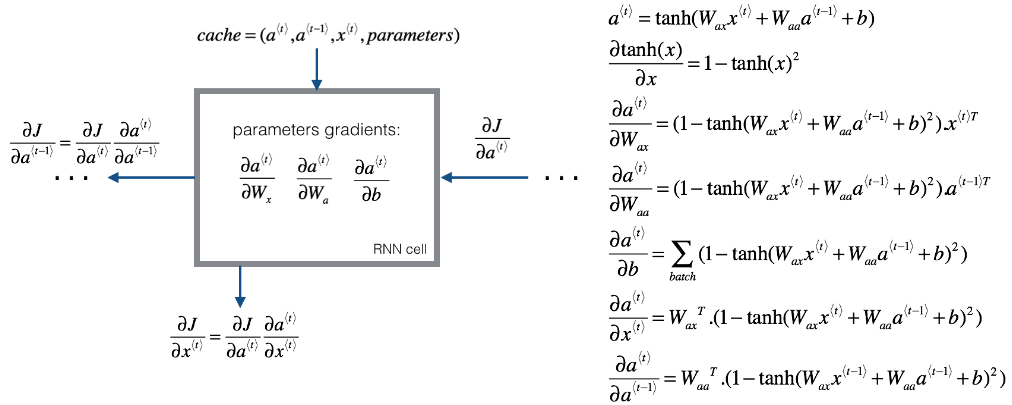
defrnn_cell_backward(da_next, cache): """ Implements the backward pass for the RNN-cell (single time-step). Arguments: da_next -- Gradient of loss with respect to next hidden state cache -- python dictionary containing useful values (output of rnn_cell_forward()) Returns: gradients -- python dictionary containing: dx -- Gradients of input data, of shape (n_x, m) da_prev -- Gradients of previous hidden state, of shape (n_a, m) dWax -- Gradients of input-to-hidden weights, of shape (n_a, n_x) dWaa -- Gradients of hidden-to-hidden weights, of shape (n_a, n_a) dba -- Gradients of bias vector, of shape (n_a, 1) """ # Retrieve values from cache (a_next, a_prev, xt, parameters) = cache # Retrieve values from parameters Wax = parameters["Wax"] Waa = parameters["Waa"] Wya = parameters["Wya"] ba = parameters["ba"] by = parameters["by"]
# compute the gradient of tanh with respect to a_next dtanh = da_next * (1 - a_next**2) # 指的是代价函数对 (Wax·x^<t>+Waa·a^<t-1>+ba) 的导数
# compute the gradient of the loss with respect to Wax dxt = np.dot(Wax.T, dtanh) dWax = np.dot(dtanh, xt.T)
# compute the gradient with respect to Waa da_prev = np.dot(Waa.T, dtanh) dWaa = np.dot(dtanh, a_prev.T)
# compute the gradient with respect to b dba = np.sum(dtanh, axis = 1, keepdims = True)
# Store the gradients in a python dictionary gradients = {"dxt": dxt, "da_prev": da_prev, "dWax": dWax, "dWaa": dWaa, "dba": dba} return gradients
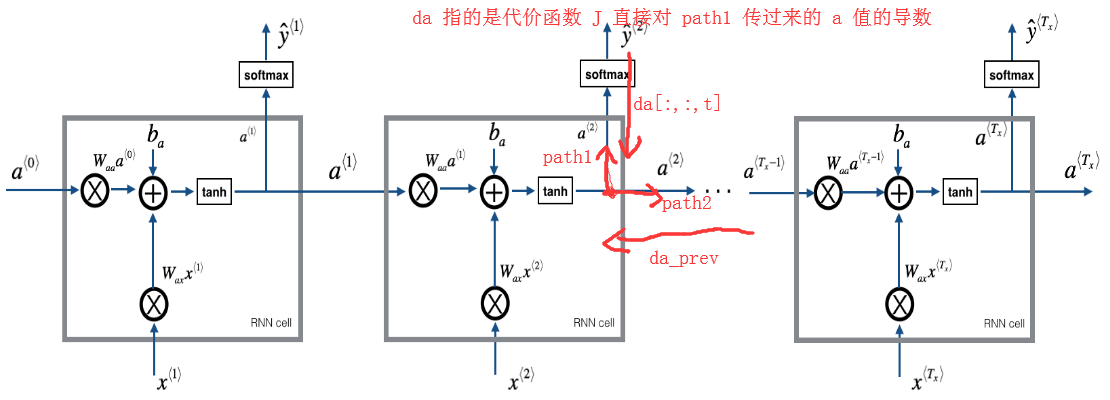
defrnn_backward(da, caches): """ Implement the backward pass for a RNN over an entire sequence of input data. Arguments: da -- Upstream gradients of all hidden states, of shape (n_a, m, T_x) caches -- tuple containing information from the forward pass (rnn_forward) Returns: gradients -- python dictionary containing: dx -- Gradient w.r.t. the input data, numpy-array of shape (n_x, m, T_x) da0 -- Gradient w.r.t the initial hidden state, numpy-array of shape (n_a, m) dWax -- Gradient w.r.t the input's weight matrix, numpy-array of shape (n_a, n_x) dWaa -- Gradient w.r.t the hidden state's weight matrix, numpy-arrayof shape (n_a, n_a) dba -- Gradient w.r.t the bias, of shape (n_a, 1) """
# Retrieve values from the first cache (t=1) of caches (caches, x) = caches (a1, a0, x1, parameters) = caches[0]
# Retrieve dimensions from da's and x1's shapes n_a, m, T_x = da.shape n_x, m = x1.shape
# initialize the gradients with the right sizes dx = np.zeros((n_x, m, T_x)) dWax = np.zeros((n_a, n_x)) dWaa = np.zeros((n_a, n_a)) dba = np.zeros((n_a, 1)) da0 = np.zeros((n_a, m)) da_prevt = np.zeros((n_a, m))
# Loop through all the time steps for t in reversed(range(T_x)): # Compute gradients at time step t. Choose wisely the "da_next" and the "cache" to use in the backward propagation step. (≈1 line) # 这里注意:a^<t> 在这里分两条路影响代价函数 J,所以 da = da[:, :, t] + da_prevt gradients = rnn_cell_backward(da[:, :, t] + da_prevt, caches[t]) # Retrieve derivatives from gradients (≈ 1 line) dxt, da_prevt, dWaxt, dWaat, dbat = gradients["dxt"], gradients["da_prev"], gradients["dWax"], gradients["dWaa"], gradients["dba"] # Increment global derivatives w.r.t parameters by adding their derivative at time-step t (≈4 lines) dx[:, :, t] = dxt # 注意:前向传播中所有 t 的 Wax、Waa、ba 都是相等的,但是每个 t 时间的 dWaxt、dWaa、dba 都是不相等的, # 它们都影响了代价函数 J,所以需要把每一个时间 t 求到的 dWaxt、dWaat、dbat 累加起来 dWax += dWaxt dWaa += dWaat dba += dbat
# Set da0 to the gradient of a which has been backpropagated through all time-steps (≈1 line) da0 = da_prevt # Store the gradients in a python dictionary gradients = {"dx": dx, "da0": da0, "dWax": dWax, "dWaa": dWaa,"dba": dba}
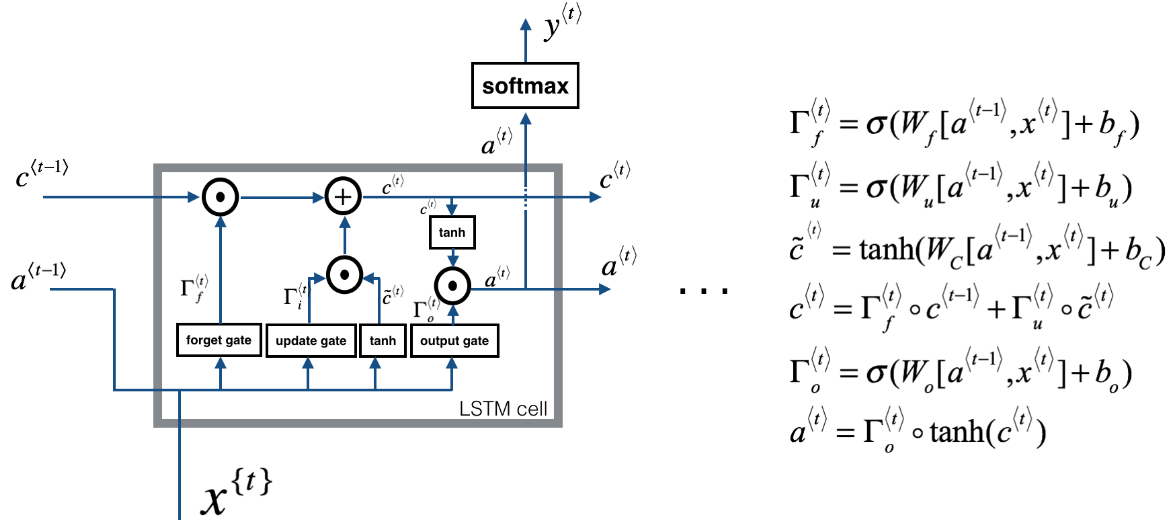
deflstm_cell_forward(xt, a_prev, c_prev, parameters): """ Implement a single forward step of the LSTM-cell as described in Figure (4) Arguments: xt -- your input data at timestep "t", numpy array of shape (n_x, m). a_prev -- Hidden state at timestep "t-1", numpy array of shape (n_a, m) c_prev -- Memory state at timestep "t-1", numpy array of shape (n_a, m) parameters -- python dictionary containing: Wf -- Weight matrix of the forget gate, numpy array of shape (n_a, n_a + n_x) bf -- Bias of the forget gate, numpy array of shape (n_a, 1) Wi -- Weight matrix of the update gate, numpy array of shape (n_a, n_a + n_x) bi -- Bias of the update gate, numpy array of shape (n_a, 1) Wc -- Weight matrix of the first "tanh", numpy array of shape (n_a, n_a + n_x) bc -- Bias of the first "tanh", numpy array of shape (n_a, 1) Wo -- Weight matrix of the output gate, numpy array of shape (n_a, n_a + n_x) bo -- Bias of the output gate, numpy array of shape (n_a, 1) Wy -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a) by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1) Returns: a_next -- next hidden state, of shape (n_a, m) c_next -- next memory state, of shape (n_a, m) yt_pred -- prediction at timestep "t", numpy array of shape (n_y, m) cache -- tuple of values needed for the backward pass, contains (a_next, c_next, a_prev, c_prev, xt, parameters) Note: ft/it/ot stand for the forget/update/output gates, cct stands for the candidate value (c tilde), c stands for the memory value """
# Retrieve parameters from "parameters" Wf = parameters["Wf"] bf = parameters["bf"] Wi = parameters["Wi"] bi = parameters["bi"] Wc = parameters["Wc"] bc = parameters["bc"] Wo = parameters["Wo"] bo = parameters["bo"] Wy = parameters["Wy"] by = parameters["by"] # Retrieve dimensions from shapes of xt and Wy n_x, m = xt.shape n_y, n_a = Wy.shape
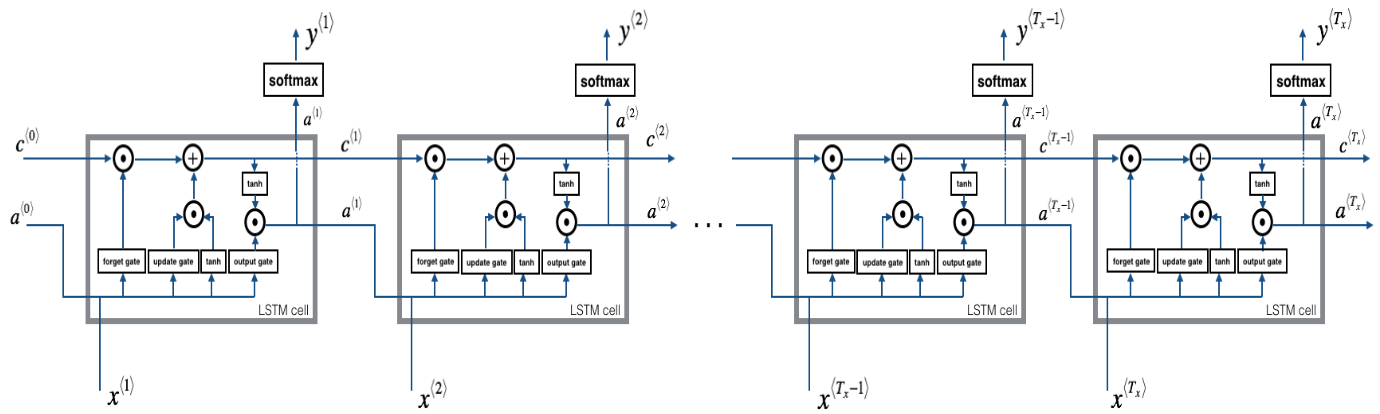
deflstm_forward(x, a0, parameters): """ Implement the forward propagation of the recurrent neural network using an LSTM-cell described in Figure (3). Arguments: x -- Input data for every time-step, of shape (n_x, m, T_x). a0 -- Initial hidden state, of shape (n_a, m) parameters -- python dictionary containing: Wf -- Weight matrix of the forget gate, numpy array of shape (n_a, n_a + n_x) bf -- Bias of the forget gate, numpy array of shape (n_a, 1) Wi -- Weight matrix of the update gate, numpy array of shape (n_a, n_a + n_x) bi -- Bias of the update gate, numpy array of shape (n_a, 1) Wc -- Weight matrix of the first "tanh", numpy array of shape (n_a, n_a + n_x) bc -- Bias of the first "tanh", numpy array of shape (n_a, 1) Wo -- Weight matrix of the output gate, numpy array of shape (n_a, n_a + n_x) bo -- Bias of the output gate, numpy array of shape (n_a, 1) Wy -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a) by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1) Returns: a -- Hidden states for every time-step, numpy array of shape (n_a, m, T_x) y -- Predictions for every time-step, numpy array of shape (n_y, m, T_x) caches -- tuple of values needed for the backward pass, contains (list of all the caches, x) """
# Initialize "caches", which will track the list of all the caches caches = []
# Retrieve dimensions from shapes of x and parameters['Wy'] n_x, m, T_x = x.shape n_y, n_a = parameters['Wy'].shape # initialize "a", "c" and "y" with zeros a = np.zeros((n_a,m,T_x)) # 存放 a 的容器 c = np.zeros((n_a,m,T_x)) # 存放 c 的容器 y = np.zeros((n_y,m,T_x)) # 存放 y 的容器 # Initialize a_next and c_next a_next = a0 c_next = np.zeros((n_a,m)) # loop over all time-steps for t in range(T_x): # Update next hidden state, next memory state, compute the prediction, get the cache a_next, c_next, yt, cache = lstm_cell_forward(x[:,:,t], a_next, c_next, parameters) # Save the value of the new "next" hidden state in a a[:,:,t] = a_next # Save the value of the prediction in y y[:,:,t] = yt # Save the value of the next cell state c[:,:,t] = c_next # Append the cache into caches caches.append(cache) # store values needed for backward propagation in cache caches = (caches, x)
deflstm_cell_backward(da_next, dc_next, cache): """ Implement the backward pass for the LSTM-cell (single time-step). Arguments: da_next -- Gradients of next hidden state, of shape (n_a, m) dc_next -- Gradients of next cell state, of shape (n_a, m) cache -- cache storing information from the forward pass Returns: gradients -- python dictionary containing: dxt -- Gradient of input data at time-step t, of shape (n_x, m) da_prev -- Gradient w.r.t. the previous hidden state, numpy array of shape (n_a, m) dc_prev -- Gradient w.r.t. the previous memory state, of shape (n_a, m, T_x) dWf -- Gradient w.r.t. the weight matrix of the forget gate, numpy array of shape (n_a, n_a + n_x) dWi -- Gradient w.r.t. the weight matrix of the update gate, numpy array of shape (n_a, n_a + n_x) dWc -- Gradient w.r.t. the weight matrix of the memory gate, numpy array of shape (n_a, n_a + n_x) dWo -- Gradient w.r.t. the weight matrix of the output gate, numpy array of shape (n_a, n_a + n_x) dbf -- Gradient w.r.t. biases of the forget gate, of shape (n_a, 1) dbi -- Gradient w.r.t. biases of the update gate, of shape (n_a, 1) dbc -- Gradient w.r.t. biases of the memory gate, of shape (n_a, 1) dbo -- Gradient w.r.t. biases of the output gate, of shape (n_a, 1) """
# Retrieve information from "cache" (a_next, c_next, a_prev, c_prev, ft, it, cct, ot, xt, parameters) = cache
# Retrieve dimensions from xt's and a_next's shape n_x, m = xt.shape n_a, m = a_next.shape # Compute gates related derivatives, you can find their values can be found by looking carefully at equations (7) to (10) dot = da_next * np.tanh(c_next)*ot*(1-ot) # 也就是 dJ / d(W_o[a^{<t-1>},x^{<t>}]+b_o),下同 dcct = (dc_next + da_next*ot*(1-np.tanh(c_next)**2))*it*(1-cct**2) dit = (dc_next + da_next*ot*(1-np.tanh(c_next)**2))*cct*it*(1-it) # it 就是更新门 updategate dft = (dc_next + da_next*ot*(1-np.tanh(c_next)**2))*c_prev*ft*(1-ft)
deflstm_backward(da, caches): """ Implement the backward pass for the RNN with LSTM-cell (over a whole sequence). Arguments: da -- Gradients w.r.t the hidden states, numpy-array of shape (n_a, m, T_x) dc -- Gradients w.r.t the memory states, numpy-array of shape (n_a, m, T_x) caches -- cache storing information from the forward pass (lstm_forward) Returns: gradients -- python dictionary containing: dx -- Gradient of inputs, of shape (n_x, m, T_x) da0 -- Gradient w.r.t. the previous hidden state, numpy array of shape (n_a, m) dWf -- Gradient w.r.t. the weight matrix of the forget gate, numpy array of shape (n_a, n_a + n_x) dWi -- Gradient w.r.t. the weight matrix of the update gate, numpy array of shape (n_a, n_a + n_x) dWc -- Gradient w.r.t. the weight matrix of the memory gate, numpy array of shape (n_a, n_a + n_x) dWo -- Gradient w.r.t. the weight matrix of the save gate, numpy array of shape (n_a, n_a + n_x) dbf -- Gradient w.r.t. biases of the forget gate, of shape (n_a, 1) dbi -- Gradient w.r.t. biases of the update gate, of shape (n_a, 1) dbc -- Gradient w.r.t. biases of the memory gate, of shape (n_a, 1) dbo -- Gradient w.r.t. biases of the save gate, of shape (n_a, 1) """
# Retrieve values from the first cache (t=1) of caches. (caches, x) = caches (a1, c1, a0, c0, f1, i1, cc1, o1, x1, parameters) = caches[0]
# Retrieve dimensions from da's and x1's shapes n_a, m, T_x = da.shape n_x, m = x1.shape # initialize the gradients with the right sizes dx = np.zeros((n_x, m, T_x)) da0 = np.zeros((n_a,m)) da_prevt = np.zeros((n_a,m)) dc_prevt = np.zeros((n_a,m)) dWf = np.zeros((n_a, n_a+n_x)) # 每个时间点 t 的 Wf 都是相等的 dWi = np.zeros((n_a,n_a+n_x)) dWc = np.zeros((n_a,n_a+n_x)) dWo = np.zeros((n_a,n_a+n_x)) dbf = np.zeros((n_a,1)) dbi = np.zeros((n_a,1)) dbc = np.zeros((n_a,1)) dbo = np.zeros((n_a,1)) # loop back over the whole sequence for t in reversed(range(T_x)): # Compute all gradients using lstm_cell_backward gradients = lstm_cell_backward(da[:,:,t], dc_prevt, caches[t]) # Store or add the gradient to the parameters' previous step's gradient dx[:,:,t] = gradients['dxt'] # 注意:前向传播中所有 t 的 Wf、Wi、Wo、Wc、ba、bi、bo、bc 都是相等的, # 但是每个 t 时间的 dWf、dWi、dWo、dWc、dba、dbi、dbo、dbc 都是不相等的, # 它们都影响了代价函数 J, # 所以需要把每一个时间 t 求到的 dWf、dWi、dWo、dWc、dba、dbi、dbo、dbc 累加起来 dWf += gradients['dWf'] dWi += gradients['dWi'] dWc += gradients['dWc'] dWo += gradients['dWo'] dbf += gradients['dbf'] dbi += gradients['dbi'] dbc += gradients['dbc'] dbo += gradients['dbo'] # Set the first activation's gradient to the backpropagated gradient da_prev. da0 = gradients['da_prev'] # Store the gradients in a python dictionary gradients = {"dx": dx, "da0": da0, "dWf": dWf,"dbf": dbf, "dWi": dWi,"dbi": dbi, "dWc": dWc,"dbc": dbc, "dWo": dWo,"dbo": dbo} return gradients
Part 2-Character level language model - Dinosaurus land
创造一个字符级的语言模型,通过一堆恐龙名字进行训练,用来生成新的恐龙名字。
1 2 3
import numpy as np from utils import * import random
问题描述
数据集加载和预处理
1 2 3 4 5
data = open('dinos.txt', 'r').read() data= data.lower() chars = list(set(data)) # 去除重复元素 data_size, vocab_size = len(data), len(chars) print('There are %d total characters and %d unique characters in your data.' % (data_size, vocab_size))
output:There are 19909 total characters and 27 unique characters in your data.
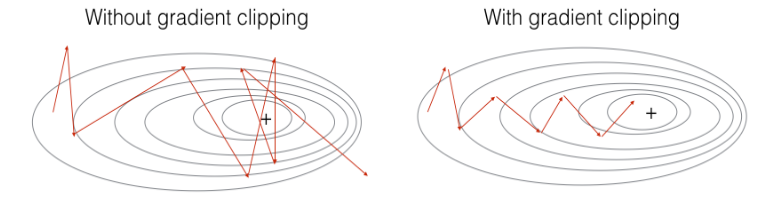
defclip(gradients, maxValue): ''' Clips the gradients' values between minimum and maximum. Arguments: gradients -- a dictionary containing the gradients "dWaa", "dWax", "dWya", "db", "dby" maxValue -- everything above this number is set to this number, and everything less than -maxValue is set to -maxValue Returns: gradients -- a dictionary with the clipped gradients. ''' dWaa, dWax, dWya, db, dby = gradients['dWaa'], gradients['dWax'], gradients['dWya'], gradients['db'], gradients['dby']
# clip to mitigate exploding gradients, loop over [dWax, dWaa, dWya, db, dby]. (≈2 lines) for gradient in [dWax, dWaa, dWya, db, dby]: np.minimum(gradient,maxValue,out=gradient) np.maximum(gradient,-maxValue,out=gradient)# 注意!!gradient 在这里只是一个临时变量,我们需要把得到的值 out 输出给它
Sampling produces variety. Say you have a list of items with probability of occurrence “car” (30%) “airplane” (70%). If you simply choose the argmax of the probability from the list then you always choose airplane which gets boring. If you alternatively “sample” from the list then 70% of the time you get airplane and 30% car. This is really important in longer sentences; if you choose the argmax you end up with the same sentence all the time (exception when multiple words have exactly same probability 50:50), but sampling gives you an interesting mix of sentences from the same list.
将采样得到的 $x^{}$ 索引值进行 one-hot 编码赋值给 x 以输入下一个循环。重复第一步直到 y 输出一个结束符 “\n”
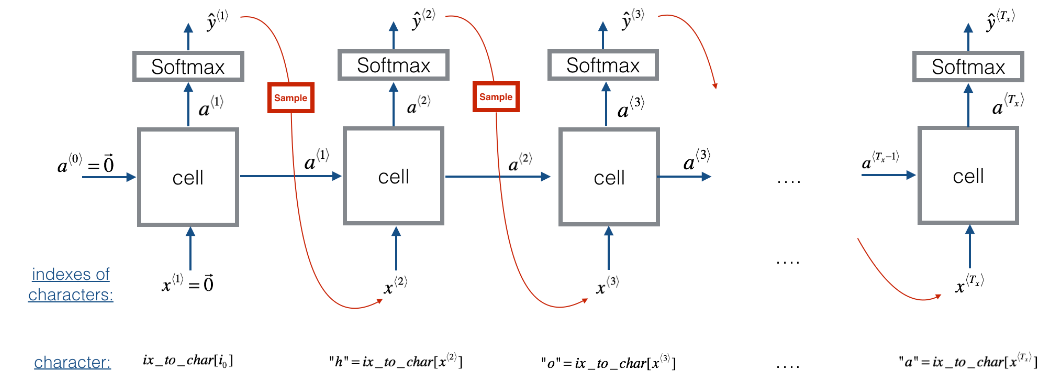
defsample(parameters, char_to_ix): """ Sample a sequence of characters according to a sequence of probability distributions output of the RNN Arguments: parameters -- python dictionary containing the parameters Waa, Wax, Wya, by, and b. char_to_ix -- python dictionary mapping each character to an index. Returns: indices -- a list of length n containing the indices of the sampled characters. """ # Retrieve parameters and relevant shapes from "parameters" dictionary Waa, Wax, Wya, by, b = parameters['Waa'], parameters['Wax'], parameters['Wya'], parameters['by'], parameters['b'] vocab_size = by.shape[0] n_a = Waa.shape[1]
# Step 1: Create the one-hot vector x for the first character (initializing the sequence generation). x = np.zeros((vocab_size,1)) # Step 1': Initialize a_prev as zeros a_prev = np.zeros((n_a,1)) # Create an empty list of indices, this is the list which will contain the list of indices of the characters to generate (≈1 line) indices = [] # 存放每一步生成的索引值 # Idx is a flag to detect a newline character, we initialize it to -1 idx = -1 # Loop over time-steps t. At each time-step, sample a character from a probability distribution and append # its index to "indices". We'll stop if we reach 50 characters (which should be very unlikely with a well # trained model), which helps debugging and prevents entering an infinite loop. counter = 0 newline_character = char_to_ix['\n'] while (idx != newline_character and counter != 50): # Step 2: Forward propagate x using the equations (1), (2) and (3) a = np.tanh(np.dot(Wax,x)+np.dot(Waa,a_prev)+b) z = np.dot(Wya,a)+by y = softmax(z) # Step 3: Sample the index of a character within the vocabulary from the probability distribution y idx = np.random.choice(vocab_size, p=y.ravel()) # 按照概率进行随机取值
# Append the index to "indices" indices.append(idx) # Step 4: Overwrite the input character as the one corresponding to the sampled index. x = np.zeros((vocab_size,1)) x[idx] = 1# one-hot 编码 # Update "a_prev" to be "a" a_prev = a counter +=1 if (counter == 50): # 限制生成的单词字长不超过 50,防止无限循环 indices.append(char_to_ix['\n']) return indices
defsmooth(loss, cur_loss): return loss * 0.999 + cur_loss * 0.001
defprint_sample(sample_ix, ix_to_char): txt = ''.join(ix_to_char[ix] for ix in sample_ix) txt = txt[0].upper() + txt[1:] # capitalize first character print ('%s' % (txt, ), end='')
defrnn_forward(X, Y, a0, parameters, vocab_size = 27): # Initialize x, a and y_hat as empty dictionaries x, a, y_hat = {}, {}, {} a[-1] = np.copy(a0) # initialize your loss to 0 loss = 0 for t in range(len(X)): # Set x[t] to be the one-hot vector representation of the t'th character in X. # if X[t] == None, we just have x[t]=0. This is used to set the input for the first timestep to the zero vector. x[t] = np.zeros((vocab_size,1)) if (X[t] != None): x[t][X[t]] = 1 # Run one step forward of the RNN a[t], y_hat[t] = rnn_step_forward(parameters, a[t-1], x[t]) # Update the loss by substracting the cross-entropy term of this time-step from it. loss -= np.log(y_hat[t][Y[t],0]) cache = (y_hat, a, x) return loss, cache
defrnn_backward(X, Y, parameters, cache): # Initialize gradients as an empty dictionary gradients = {} # Retrieve from cache and parameters (y_hat, a, x) = cache Waa, Wax, Wya, by, b = parameters['Waa'], parameters['Wax'], parameters['Wya'], parameters['by'], parameters['b'] # each one should be initialized to zeros of the same dimension as its corresponding parameter gradients['dWax'], gradients['dWaa'], gradients['dWya'] = np.zeros_like(Wax), np.zeros_like(Waa), np.zeros_like(Wya) gradients['db'], gradients['dby'] = np.zeros_like(b), np.zeros_like(by) gradients['da_next'] = np.zeros_like(a[0])
# Backpropagate through time for t in reversed(range(len(X))): dy = np.copy(y_hat[t]) dy[Y[t]] -= 1 gradients = rnn_step_backward(dy, gradients, parameters, x[t], a[t], a[t-1]) return gradients, a
defoptimize(X, Y, a_prev, parameters, learning_rate = 0.01): """ Execute one step of the optimization to train the model. Arguments: X -- list of integers, where each integer is a number that maps to a character in the vocabulary. Y -- list of integers, exactly the same as X but shifted one index to the left. a_prev -- previous hidden state. parameters -- python dictionary containing: Wax -- Weight matrix multiplying the input, numpy array of shape (n_a, n_x) Waa -- Weight matrix multiplying the hidden state, numpy array of shape (n_a, n_a) Wya -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a) b -- Bias, numpy array of shape (n_a, 1) by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1) learning_rate -- learning rate for the model. Returns: loss -- value of the loss function (cross-entropy) gradients -- python dictionary containing: dWax -- Gradients of input-to-hidden weights, of shape (n_a, n_x) dWaa -- Gradients of hidden-to-hidden weights, of shape (n_a, n_a) dWya -- Gradients of hidden-to-output weights, of shape (n_y, n_a) db -- Gradients of bias vector, of shape (n_a, 1) dby -- Gradients of output bias vector, of shape (n_y, 1) a[len(X)-1] -- the last hidden state, of shape (n_a, 1) """ # Forward propagate through time (≈1 line) loss, cache = rnn_forward(X, Y, a_prev, parameters) # Backpropagate through time (≈1 line) gradients, a = rnn_backward(X, Y, parameters, cache) # Clip your gradients between -5 (min) and 5 (max) (≈1 line) gradients = clip(gradients, 5) # Update parameters (≈1 line) parameters = update_parameters(parameters, gradients, learning_rate)
defmodel(data, ix_to_char, char_to_ix, num_iterations = 35000, n_a = 50, dino_names = 7, vocab_size = 27): """ Trains the model and generates dinosaur names. Arguments: data -- text corpus ix_to_char -- dictionary that maps the index to a character char_to_ix -- dictionary that maps a character to an index num_iterations -- number of iterations to train the model for n_a -- number of units of the RNN cell dino_names -- number of dinosaur names you want to sample at each iteration. vocab_size -- number of unique characters found in the text, size of the vocabulary Returns: parameters -- learned parameters """ # Retrieve n_x and n_y from vocab_size n_x, n_y = vocab_size, vocab_size # Initialize parameters parameters = initialize_parameters(n_a, n_x, n_y) # Initialize loss (this is required because we want to smooth our loss, don't worry about it) loss = get_initial_loss(vocab_size, dino_names) # Build list of all dinosaur names (training examples). with open("dinos.txt") as f: examples = f.readlines() examples = [x.lower().strip() for x in examples] # Shuffle list of all dinosaur names np.random.shuffle(examples) # 将样本洗牌 # Initialize the hidden state of your LSTM a_prev = np.zeros((n_a, 1)) # Optimization loop for j in range(num_iterations): # 假设 n 个恐龙名字样本 # 样本1(循环1)-> 样本2(循环2)->……-> 样本n(循环n)->样本1(循环n+1)-> ……->样本n(循环2n)->…… # Use the hint above to define one training example (X,Y) (≈ 2 lines) index = j % len(examples) # 目前的循环次数取余样本数 X = [None] + [char_to_ix[ch] for ch in examples[index]] # [None] 指第一个X<0>,它生成hatY<1>,即X<n>生成hatY<n+1> Y = X[1:] + [char_to_ix["\n"]] # Y 的真实值,与 X 相同,只是没有第一个Y<0>,并且最后加上结束符,比X向右移动了一位 # Perform one optimization step: Forward-prop -> Backward-prop -> Clip -> Update parameters # Choose a learning rate of 0.01 curr_loss, gradients, a_prev = optimize(X, Y, a_prev, parameters, learning_rate = 0.01) # Use a latency trick to keep the loss smooth. It happens here to accelerate the training. loss = smooth(loss, curr_loss)
# Every 2000 Iteration, generate "n" characters thanks to sample() to check if the model is learning properly if j % 2000 == 0: print('Iteration: %d, Loss: %f' % (j, loss) + '\n') # The number of dinosaur names to print for name in range(dino_names): # Sample indices and print them sampled_indices = sample(parameters, char_to_ix, seed) print_sample(sampled_indices, ix_to_char) print('\n') return parameters
from __future__ import print_function import IPython import sys from music21 import * import numpy as np from grammar import * from qa import * from preprocess import * from music_utils import * from data_utils import * from keras.models import load_model, Model from keras.layers import Dense, Activation, Dropout, Input, LSTM, Reshape, Lambda, RepeatVector from keras.initializers import glorot_uniform from keras.utils import to_categorical from keras.optimizers import Adam from keras import backend as K
问题描述
加载数据集
先不管具体的音乐理论和细节,直接加载需要的数据集:
1 2 3 4 5 6
X, Y, n_values, indices_values = load_music_utils() print('shape of X:', X.shape) print('number of training examples:', X.shape[0]) print('Tx (length of sequence):', X.shape[1]) print('total # of unique values:', n_values) print('Shape of Y:', Y.shape)
shape of X: (60, 30, 78) number of training examples: 60 Tx (length of sequence): 30 total # of unique values: 78 Shape of Y: (30, 60, 78)
X:(m, T_x, 78) 其中 m 是样本数,T_x 是音乐片段的时间,78 是 one-hot 向量的长度
Y:(T_y, m, 78) 为了便于 feed 给 LSTM 层,将其维度变一下
n_value:把某个时间的音乐变成 one-hot 向量的长度
indices_values:78 个索引值的字典
模型概况
每个训练用的序列样本长度可以是不同的,但是这里为了方便向量化,将所有用以训练的样本统一长度为 30 s.
所以在下面的函数中使用 for 循环调用 LSTM 层 T_x 次,由于每个时间点的 LSTM 层的参数都是一样的,所以我们定义一个全局的 层 对象,每个 for 循环都调用这个对象,实现参数共享。
1 2 3
reshapor = Reshape((1, 78)) # Used in Step 2.B of djmodel(), below LSTM_cell = LSTM(n_a, return_state = True)# return_state 返回 c # Used in Step 2.C densor = Dense(n_values, activation='softmax') # Used in Step 2.D
建立模型的步骤是:
建立空列表 outputs 储存每个时间点的输出 $\hat y$
for t in 1,…, T_x:
从输入选择第 t 个时间点的序列值
使用 x = Lambda(lambda x: X[:,t,:])(X),输出维度是 (?, 78)
调用 reshapor 把 (?,78)->(?,1,78),便于输入 LSTM 层
调用 LSTM_cell 得到输出的 a 和 c
a, _, c = LSTM_cell(input_x, initial_state=[previous hidden state, previous cell state])
defdjmodel(Tx, n_a, n_values): """ Implement the model Arguments: Tx -- length of the sequence in a corpus n_a -- the number of activations used in our model n_values -- number of unique values in the music data Returns: model -- a keras model with the """ # Define the input of your model with a shape X = Input(shape=(Tx, n_values)) # Keras 中 shape 不需要显式地指出样本数 m,第一个位置默认是样本数,打印 X 的形状为 (?, 30, 78) # Define s0, initial hidden state for the decoder LSTM a0 = Input(shape=(n_a,), name='a0')#shape 其实是(?,n_a,) c0 = Input(shape=(n_a,), name='c0') a = a0 c = c0
# Step 1: Create empty list to append the outputs while you iterate (≈1 line) outputs = [] # Step 2: Loop for t in range(Tx): # Step 2.A: select the "t"th time step vector from X. x = Lambda(lambda x: X[:,t,:])(X)# Lambda 层是对 X 整个进行运算,得到一个结果,所以直接返回 X[:,t,:] # Step 2.B: Use reshapor to reshape x to be (1, n_values) (≈1 line) x = reshapor(x) # (?,78)->(?,1,78) # Step 2.C: Perform one step of the LSTM_cell a, _, c = LSTM_cell(x, initial_state=[a, c]) # Step 2.D: Apply densor to the hidden state output of LSTM_Cell out = densor(a) # Step 2.E: add the output to "outputs" outputs.append(out) # Step 3: Create model instance model = Model(inputs=[X,a0,c0], outputs=outputs)
defmusic_inference_model(LSTM_cell, densor, n_values = 78, n_a = 64, Ty = 100): """ Uses the trained "LSTM_cell" and "densor" from model() to generate a sequence of values. Arguments: LSTM_cell -- the trained "LSTM_cell" from model(), Keras layer object densor -- the trained "densor" from model(), Keras layer object n_values -- integer, umber of unique values n_a -- number of units in the LSTM_cell Ty -- integer, number of time steps to generate Returns: inference_model -- Keras model instance """ # Define the input of your model with a shape x0 = Input(shape=(1, n_values)) # Define s0, initial hidden state for the decoder LSTM a0 = Input(shape=(n_a,), name='a0') c0 = Input(shape=(n_a,), name='c0') a = a0 c = c0 x = x0
# Step 1: Create an empty list of "outputs" to later store your predicted values (≈1 line) outputs = [] # Step 2: Loop over Ty and generate a value at every time step for t in range(Ty): # Step 2.A: Perform one step of LSTM_cell (≈1 line) a, _, c = LSTM_cell(x,initial_state=[a,c]) # Step 2.B: Apply Dense layer to the hidden state output of the LSTM_cell (≈1 line) out = densor(a)
# Step 2.C: Append the prediction "out" to "outputs". out.shape = (None, 78) (≈1 line) outputs.append(out) # Step 2.D: Select the next value according to "out", and set "x" to be the one-hot representation of the # selected value, which will be passed as the input to LSTM_cell on the next step. We have provided # the line of code you need to do this. x = Lambda(one_hot)(out) # 下一次的输入等于上一次的输出变成 one-hot 向量 # Step 3: Create model instance with the correct "inputs" and "outputs" (≈1 line) inference_model = Model(inputs=[x0,a0,c0], outputs = outputs)
defpredict_and_sample(inference_model, x_initializer = x_initializer, a_initializer = a_initializer, c_initializer = c_initializer): """ Predicts the next value of values using the inference model. Arguments: inference_model -- Keras model instance for inference time x_initializer -- numpy array of shape (1, 1, 78), one-hot vector initializing the values generation a_initializer -- numpy array of shape (1, n_a), initializing the hidden state of the LSTM_cell c_initializer -- numpy array of shape (1, n_a), initializing the cell state of the LSTM_cel Returns: results -- numpy-array of shape (Ty, 78), matrix of one-hot vectors representing the values generated indices -- numpy-array of shape (Ty, 1), matrix of indices representing the values generated """
# Step 1: Use your inference model to predict an output sequence given x_initializer, a_initializer and c_initializer. pred = inference_model.predict([x_initializer, a_initializer, c_initializer]) # Step 2: Convert "pred" into an np.array() of indices with the maximum probabilities indices = np.argmax(pred,axis=-1) # 将 softmax 输出中概率值最大的定为输出索引值 # Step 3: Convert indices to one-hot vectors, the shape of the results should be (1, ) results = to_categorical(indices, num_classes=n_values) # 将索引值再变成 one-hot 向量