
在“序列化模型”这门课的第一周,我们会学习到循环神经网络,这种模型对时间数据表现得非常好,它有几个变种,包括 LSTM,GRU 和 双向 RNN。
序列化模型
序列化模型的例子
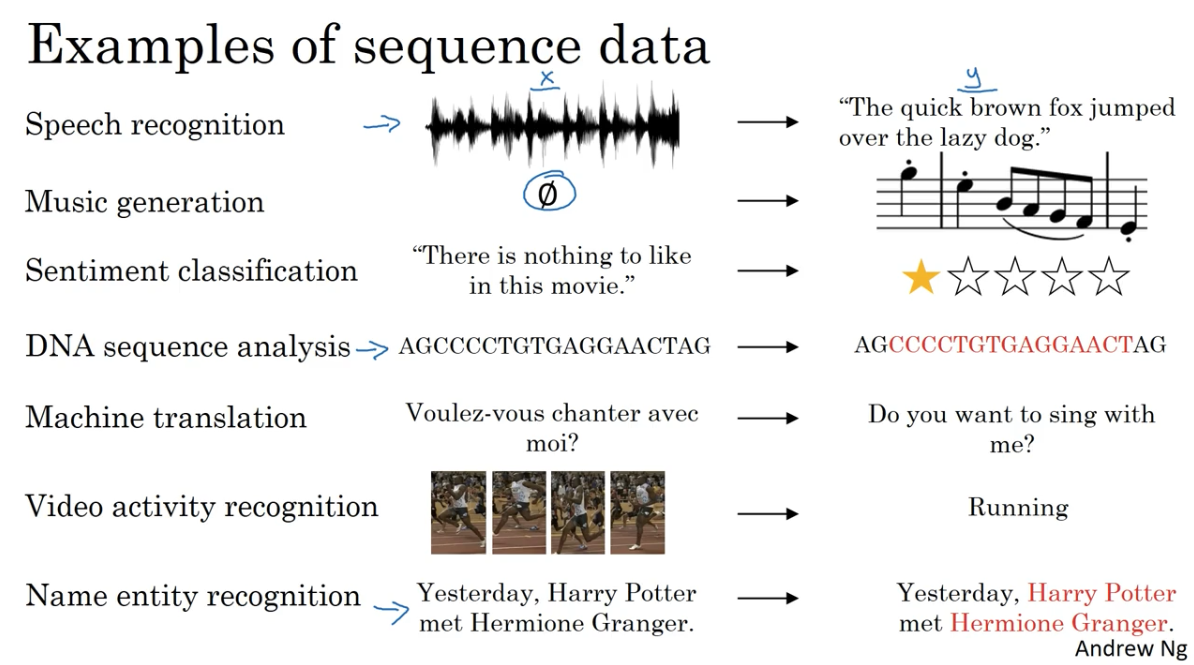
标注
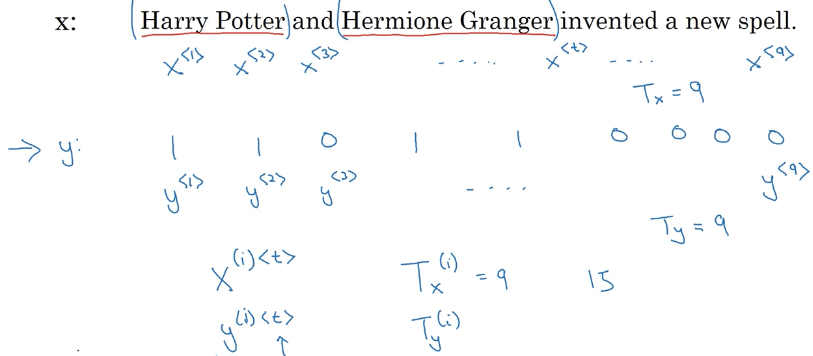
假如我们输入一句话 x,如果要找出其中的人名,那么输出标签对应人名的位置取 1.
- $T_x,T_y$ 表示这个序列的长度
- 上标 $(i)$ 表示第 i 个样本,上标
<t>表示这个序列的第 t 个位置
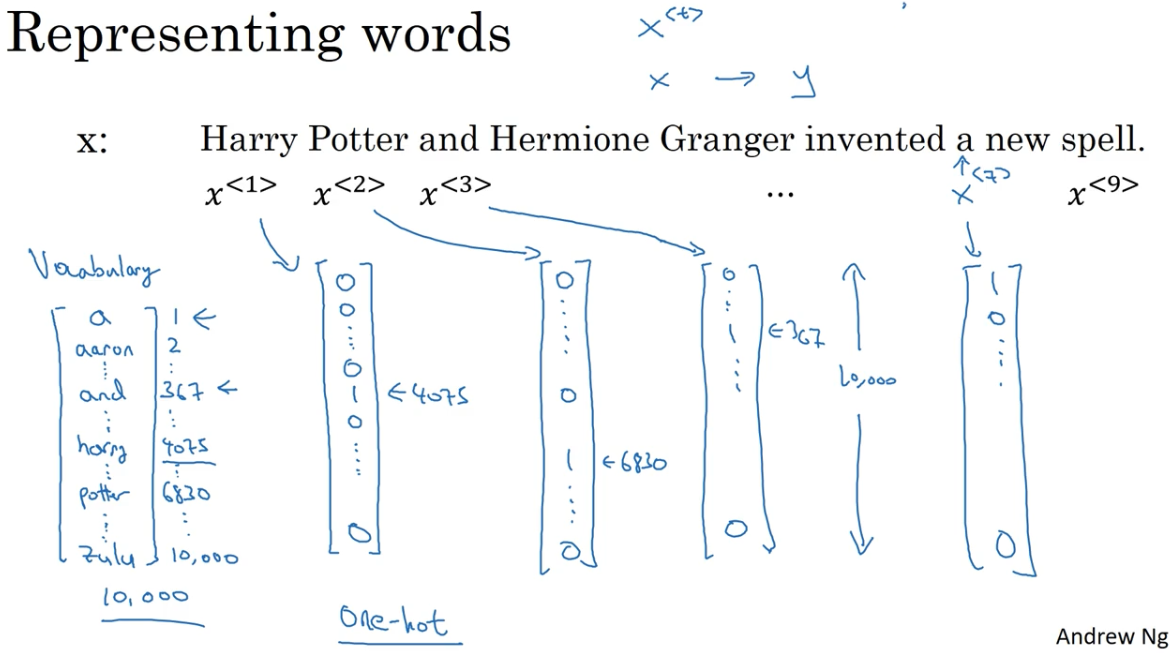
为了表示输入句子 x,我们需要建立一个字典,在这个例子里用的是词汇量为 10,000 的字典,对于现代的自然语言处理应用而言, 这种规模属于非常小的了,对于商业级的应用,字典规模一般为 3 到 5 万词汇,10 万级词汇的字典也比较常见。构建这个字典的一个方法就是去训练集中查找,找到出现频率最高的 1 万个词,另一种方式是查找一些网上的字典,将其中包含的英语中最常见的 1 万词作为拟构建的字典。
然后对输入句子进行 one-hot 编码,句子里的任意一个词 t,设为 $x^{< t >}$,都将表示为一个 one-hot 向量,one-hot 的意思指只有一位为 1 其余位全是 0。例如 $x^{< 1 >}$ 代表的单词 Harry, 就被表示为一个向量:向量的其余位全为 0,除了在第 4075 位上有一个 1 ,因为 Harry 这个单词就在词汇表中的第 4075 位上。
循环神经网络
为什么不能用标准神经网络
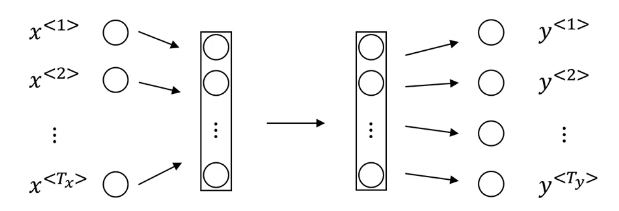
之所以不能用上图中的标准神经网络,是因为有一些问题:
- 不同样本的输入输出长度可能不同
- 无法共享从句子不同地方学习到的特征
什么是循环神经网络 Recurrent Neural Network
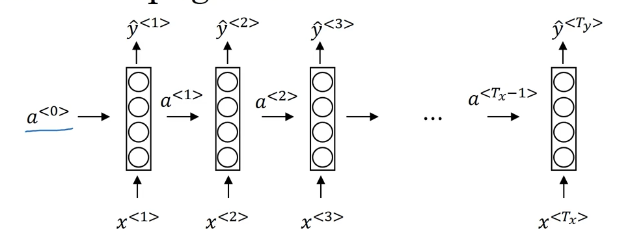
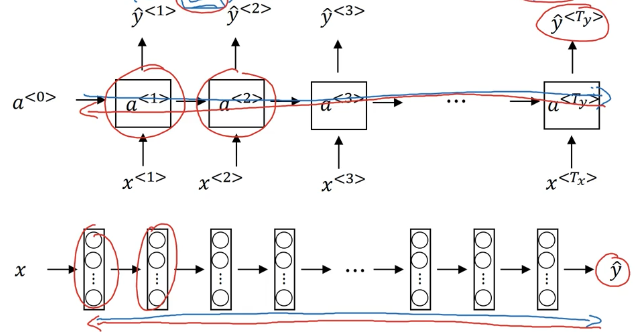
读取第一个词语 $x^{< 1>}$,输入一个神经网络,形成第一个神经网络的隐藏层,然后得到第一个词语的输出 $\hat y^{< 1>}$,第一个神经网络的激活值 $a^{< 1>}$,乘上一个参数后继续加到下一个词语的神经网络中供其使用,然后再继续往下传递,于是每一步都可以使用到先前的信息进行预测。
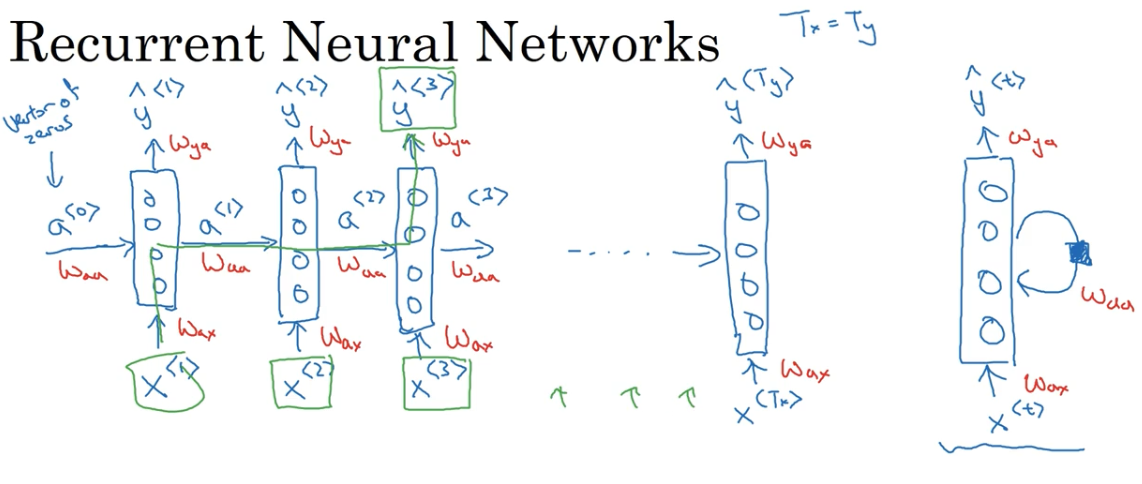
这个模型的一个缺点就是: 在序列中对某一时间的预测仅使用之前的输入, 而不使用序列中之后的信息,具体来说,当我们预测 y3 时,它不会使用关于词语 x4, x5, x6 等的信息。使用双向 RNN 可以解决这个问题。
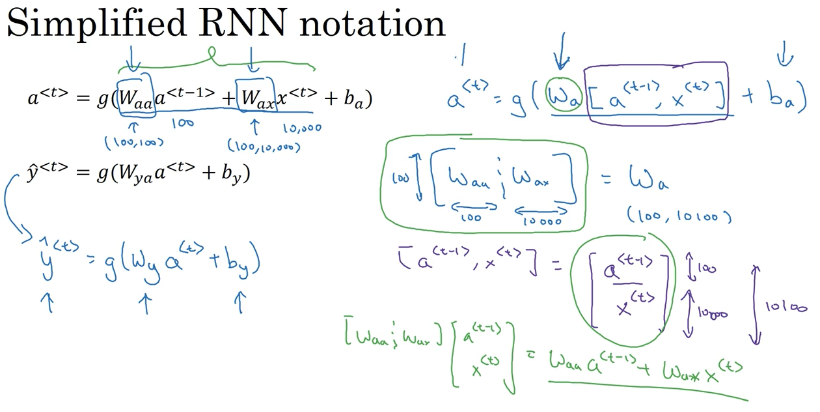
RNN 的前向传播
前向传播简化
RNN 的反向传播
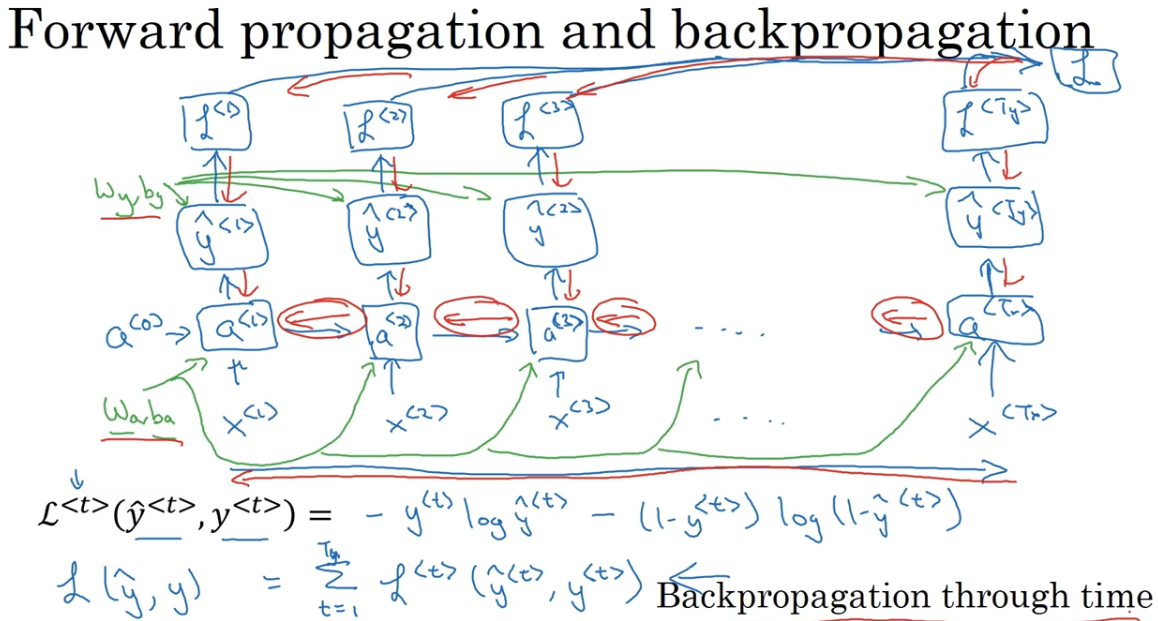
红线是反向传播的路径,绿线是前向传播的路径,一个很酷的名字,基于时间的反向传播。
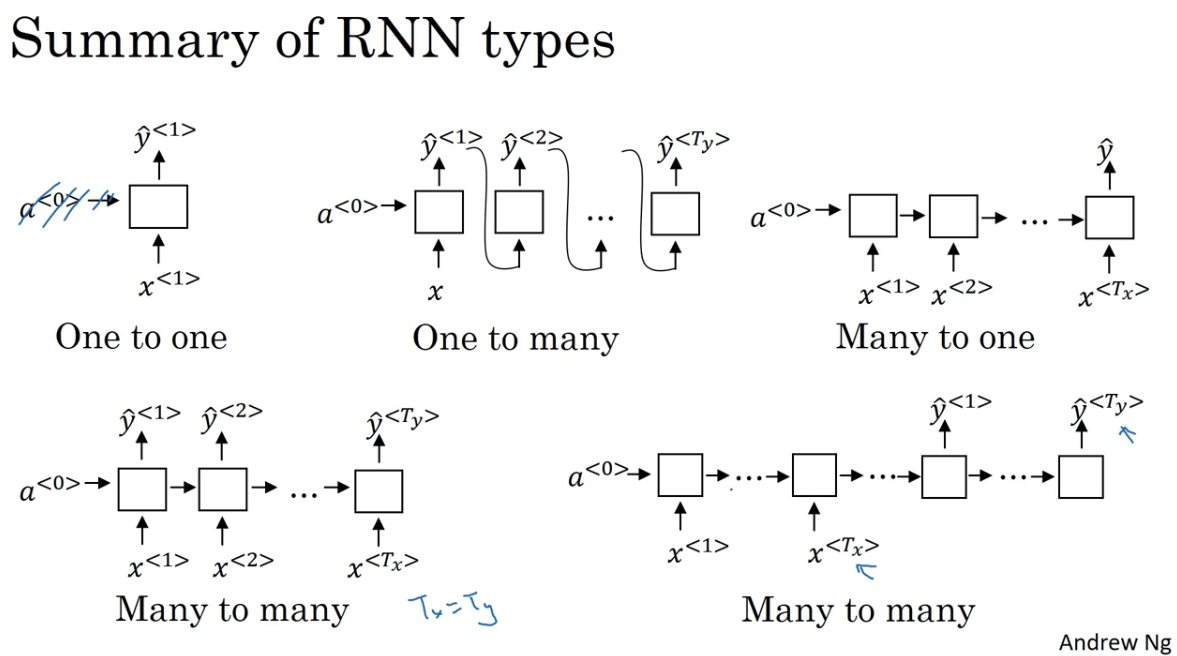
更多 RNN 的类型
目前为止,我们学习的都是输入序列和输出序列模型长度相同的模型,但是它们很多时候是不同的。
- one-to-one:标准神经网络
- many-to-many
- $T_x=T_y$: 比如输入一句话输出其中人名
- $T_x \not= T_y$:比如机器翻译,输入法语,输出英语
- many-to-one:例如情感分析,输入一句话输,出情感值
- one-to-many:例如音乐生成,输入一个和弦,输出一首歌的音符序列
语言模型和序列生成
什么是语言模型
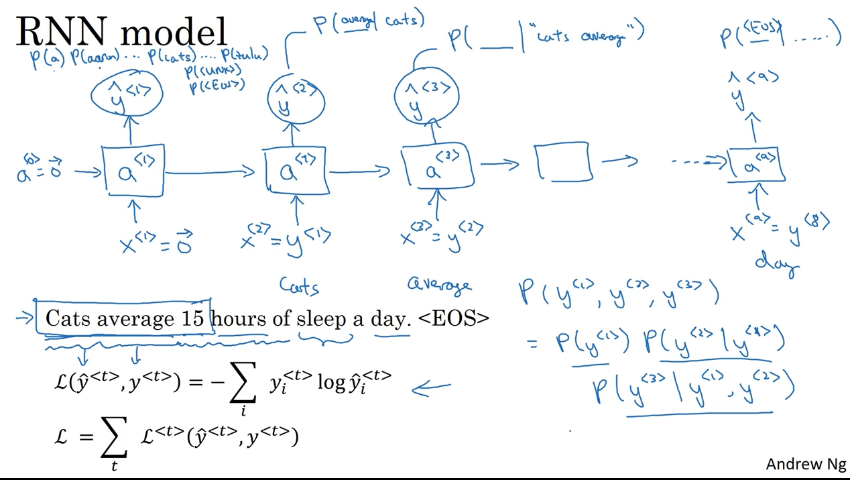
给定任何句子序列 $y^{< 1 >},y^{< 2 >},…,y^{< T_y >}$,它都能给出这个特定句子的概率 $P(y^{< 1>},y^{< 2>},…,y^{< T_y>})$,也就是说你在任何一个时空听到一句话,它是 $y^{< 1>},y^{< 2>},…,y^{< T_y>}$的概率,例如下面这个语音识别的例子。

如何用 RNN 构建语言模型
- 训练集:一个很大的语料库 corpus
- 首先将一句话标记化 Tokenize
- 每一个单词被转化为一个 one-hot 向量
- 句子末尾可以加一个
<EOS>(end of sentence) 标记表示这是句子的末尾 - 对于不在语料库中的单词,使用一个统一标记
<UNK>(unknown)
采样新序列
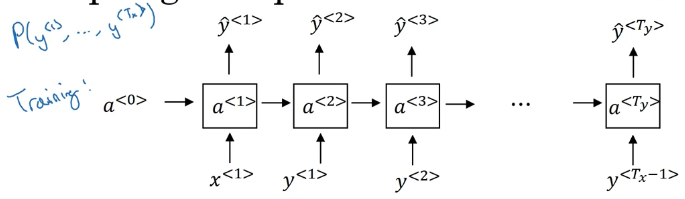
我们训练语言模型的时候使用下面的结构:
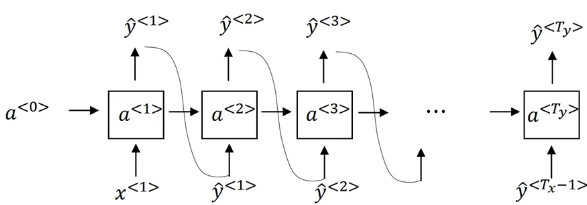
但是在采样的时候,或者说要生成一个随机选择的句子,我们直接将前一层的预测值输入下一层作为下一层的输入。
目前我们建立的是词一级的语言模型,
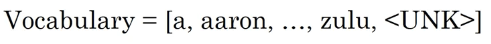
我们还可以建立字符级的语言模型,找出句子里所有可能出现的字符,并用来定义词汇表。
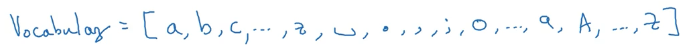
于是序列变成训练数据的每个字符而不是每个单词,这样做不用担心出现字符表中未出现的字符,但是最终会有更长的序列,需要更多计算资源。
更多的 RNN 类型
RNN 中的梯度消失问题
有两句话:
- The cat which already ate a bunch of food that was delicious was full.
- The cats which already ate a bunch of food that was delicious were full.
cat 搭配 was,cats 搭配 were,但是他们之间隔的非常远,具有很长的依赖关系,对于 RNN 来说很难处理这种长依赖关系,为什么?
与深度网络类似,较深的 RNN 也会产生梯度消失的问题,导致那么从输出 y 得到的梯度很难反向传播去影响前期层的权重,所以很难让句子前方的文字与后面的文字产生依赖关系。这导致了 RNN 的附近效应,意味着序列某个位置的的值主要受它附近的值的影响,很难做到通过各种方式反向传播到序列的开始,从而去修改神经网络在序列前期做的计算,所以这是 RNN 算法的一个缺点。
RNN 也可能产生梯度爆炸的问题,导致参数变得很大,一个解决方案是 gradient clipping,也就是如果梯度大于某些临界值,重新缩放某些梯度向量,使其不那么大。
下面是一些解决 RNN 梯度消失的方法。
门控回归单元 Gated Recurrent Unit (GRU)
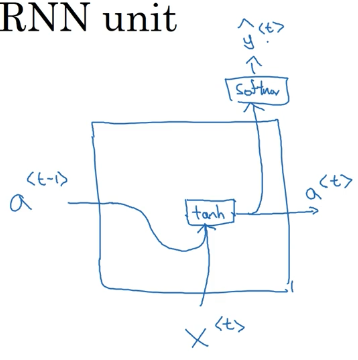
我们首先用一个图解释普通的 RNN 单元是如何工作:
简化版 GRU 原理
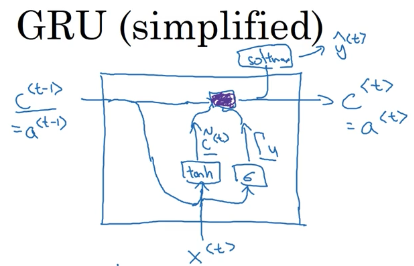
仍然是为了解决类似 The cat which already ate a bunch of food that was delicious was full. 这种句子前后长期依赖的问题,我们引入一个新的变量 c = memory cell,即记忆细胞,GRU 中主要的计算公式为:
- $c^{< t>}$ 是记忆细胞的值,等于某个时间的激活值
- $ \tilde { c } ^ { < t > }$ 是用以取代 $c^{< t>}$ 的候选值,我们可以理解为现在这个 t 时间点的信息
- $\Gamma _ { u }$ 是一个“门 (gate)”,由于是 sigmoid 函数的输出,所以是一个介于 0~1 之间的值,但是大部分值都非常接近 1 或者非常接近 0,u 代表 update,实现一个类似筛选器的作用,它决定了我们是否用 $ \tilde { c } ^ { < t > }$ 取代 $c^{< t-1>}$。
- * 表示逐元素相乘
- ${ c ^ { < t > } = \Gamma _ { u } \cdot \tilde { c } ^ { < t > } + \left( 1 - \Gamma _ { u } \right) \cdot c ^ { < t - 1 > } } $ 这是一种类似于滑动平均的公式,$ \tilde { c } ^ { < t > }$ 可以理解为现在这个 t 时间点的信息,当门值 $\Gamma _u$ 为 1 时,我们将过去积累的信息 $c^{< t-1>}$ 丢弃,更新为现在的信息 $ \tilde { c } ^ { < t > }$,当门值 $\Gamma _u$ 为 0 时,这个单元将记住过去积累的信息。而 $\Gamma _u$ 的值到底是 1 还是 0,就由模型自己学习。
分析:cat 这个词是第三人称单数,对后面谓语有影响,所以到这个词时,门值 $\Gamma _ { u }=1$,根据最后一个式子,$c^{< t>}=\tilde c^{< t>}$,即在此处我们的记忆细胞的信息发生了一次更新,好,它现在记住了这里有个第三人称单数的 cat,接着到 which、already、ate 等单词时,他们的门值 $\Gamma _ { u }=0$,$c^{< t>}= c^{< t-1>}$,也就是说,这些词对谓语 was 不存在影响,记忆细胞的值不需要更新,仍旧等于上一个旧值。也就是说 cat 这个词的信息可以一直往后产生影响。
用一个相似的图来表示 GRU 的原理:
完全的 GRU 单元
- 新增加的门 $\Gamma_r$ (r 代表 relevant),说明了 $c^{< t-1>}$ 对于计算候选值 $ \tilde { c } ^ { < t > }$ 有多大的相关性
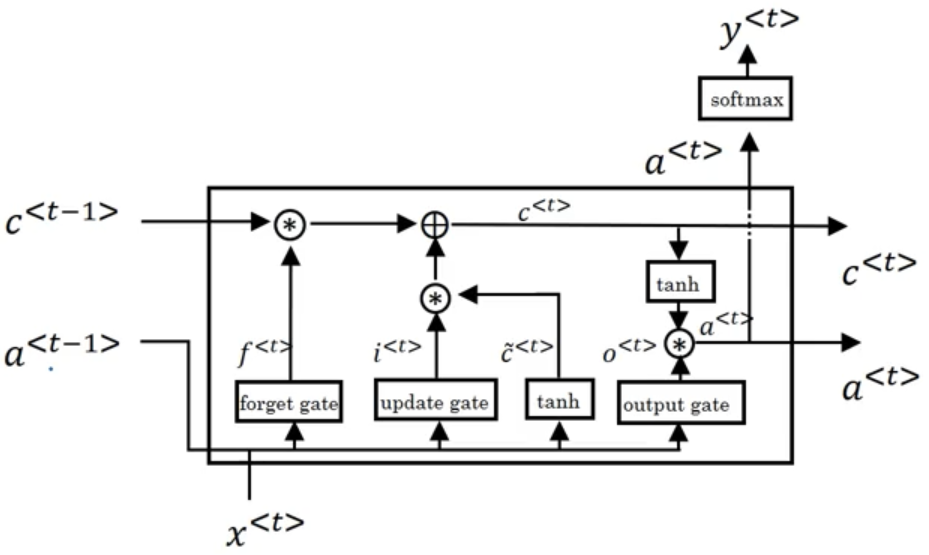
长短时记忆网络 Long Short Term Memory (LSTM)
LSTM 与 GRU 相比具有三个“门”—— 更新门、遗忘门和输出门。
一个长短时记忆单元:
我们可以将几个 LSTM 单元用以下的方式结合起来:
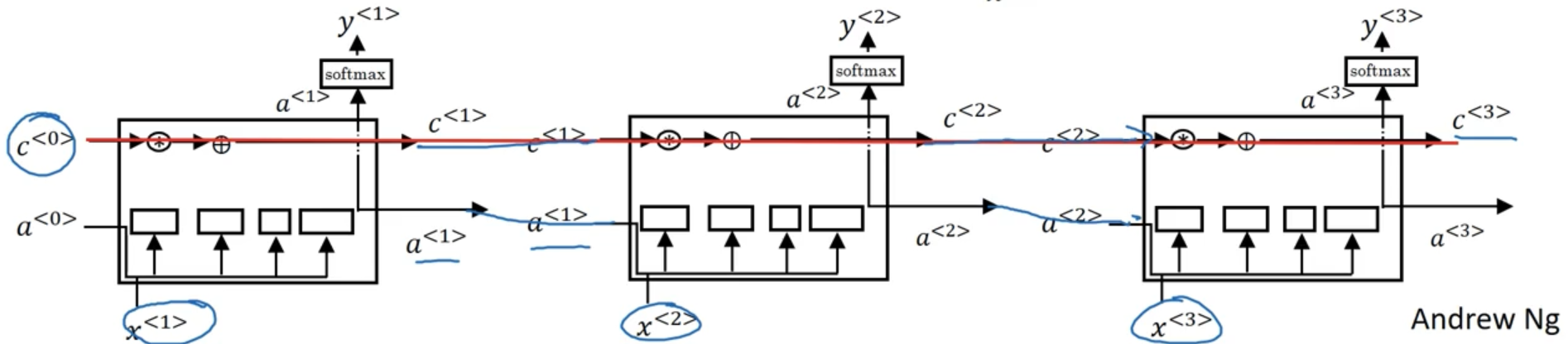
过去时间的信息 $c^{< t>}$ 在红线这条独立的路径中向前传播,所以之前的信息能维持很长时间。
LSTM 有一个变体“窥空连接 (peephole connection)”,即 $c^{< t-1>}$ 会影响门控的数值:
GRU 和 LSTM 的选择
什么时候你应该使用 LSTM,什么时候使用 GRU?
在深度学习的历史中,LSTM 要远远早于 GRU,GRU 是一个相对近期的发明,用来作为复杂的 LSTM 模型的简化。在不同的问题上不同的算法各有千秋,所以,不存在一个普适的优秀算法 。GRU 的优点是其模型的简单性,因此更适用于构建较大的网络,它只有两个门控,从计算角度看,它的效率更高,可扩展性有利于构筑较大的模型;但是 LSTM 更加的强大和灵活,因为它具有三个门控。
LSTM 是经过历史检验的方法,因此,如果要选取一个,大多数人会把 LSTM 作为默认第一个去尝试的方法。但在过去几年 GRU 的势头越来越猛, 越来越多的团队同时也用 GRU,因为其简单而且效果可以和 LSTM 比拟,可以更容易的将其扩展到更大的问题。
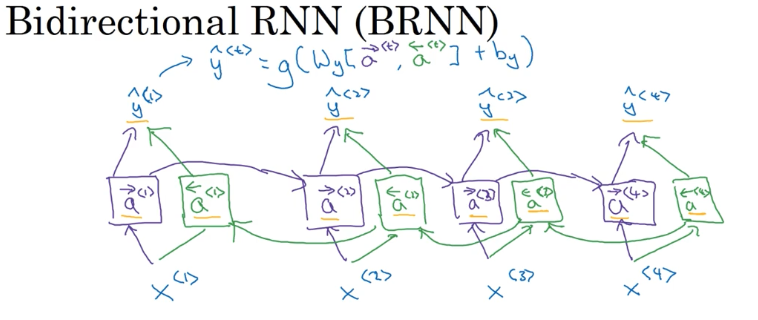
双向 RNN BIdirectional RNN (BRNN)
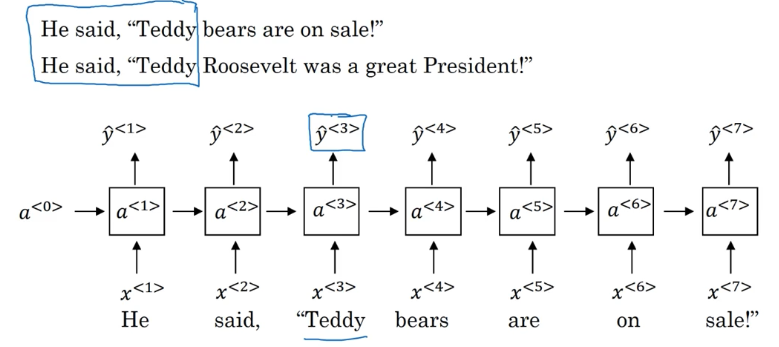
为了在某个时间点的预测获得序列前部分和后部分的信息,例如为了知道 teddy 到底是指人名还是“泰迪熊”,只凭借该词前面的信息是无法知道的,必须利用该词后面的信息。
BRNN 的结构如下图所示:
为了预测 y3 的值,我们会利用到所有的信息,如下图的黄色线条显示了信息的流动过程:
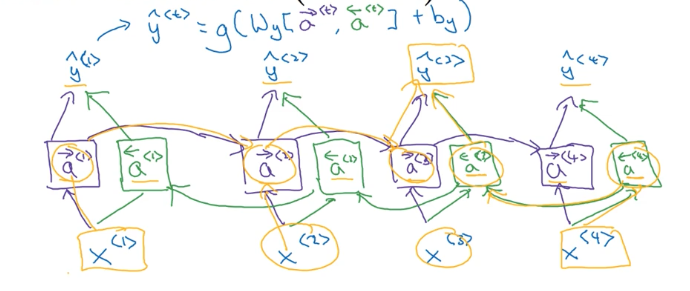
图中的每个方块既可以是 GRU 单元,也可以是 LSTM 单元。
双向 RNN 的缺点是需要整个数据序列,然后才能在任何地方进行预测。例如, 如果要构建语音识别系统,使用 BRNN 需要等待人停止说话,得到整短话,才可以实际处理它。但对于许多自然语言处理应用,可以得到整个句子,标准 BRNN 算法实际上是非常有效的。
深度 RNN
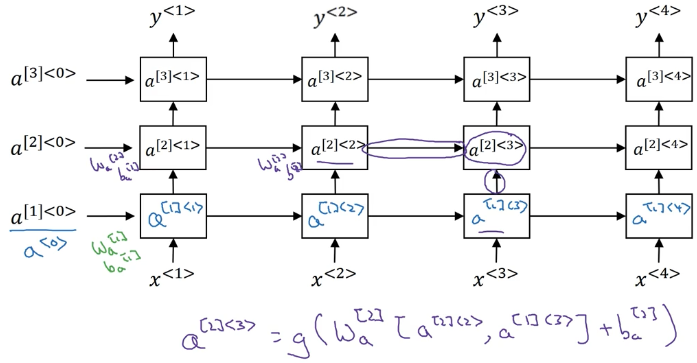
$a^{[t]}$ 表示第 t 层,这一层所有的参数都是相同的 $W_a^{[t]},b_a^{[t]}$.
由于存在时间这个维度,就算很少的层数网络都变得非常大,所以 RNN 模型的层数都不会很深。

