import argparse import os import matplotlib.pyplot as plt from matplotlib.pyplot import imshow import scipy.io import scipy.misc import numpy as np import pandas as pd import PIL import tensorflow as tf from keras import backend as K # K 相当于 keras.backend.K from keras.layers import Input, Lambda, Conv2D from keras.models import load_model, Model from yolo_utils import read_classes, read_anchors, generate_colors, preprocess_image, draw_boxes, scale_boxes from yad2k.models.keras_yolo import yolo_head, yolo_boxes_to_corners, preprocess_true_boxes, yolo_loss, yolo_body
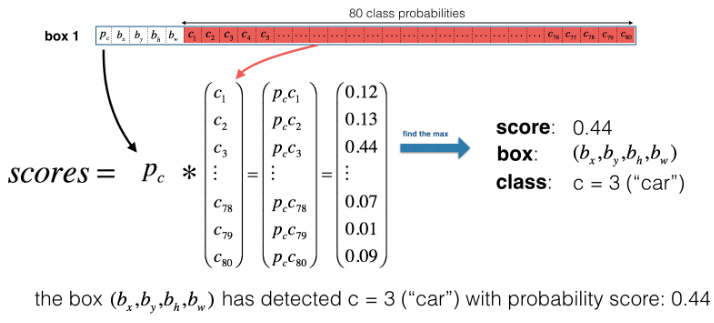
# 筛选掉分数较低的方框 defyolo_filter_boxes(box_confidence, boxes, box_class_probs, threshold = .6): """Filters YOLO boxes by thresholding on object and class confidence. Arguments: box_confidence -- tensor of shape (19, 19, 5, 1) boxes -- tensor of shape (19, 19, 5, 4) box_class_probs -- tensor of shape (19, 19, 5, 80) threshold -- real value, if [ highest class probability score < threshold], then get rid of the corresponding box Returns: scores -- tensor of shape (None,), containing the class probability score for selected boxes boxes -- tensor of shape (None, 4), containing (b_x, b_y, b_h, b_w) coordinates of selected boxes classes -- tensor of shape (None,), containing the index of the class detected by the selected boxes Note: "None" is here because you don't know the exact number of selected boxes, as it depends on the threshold. For example, the actual output size of scores would be (10,) if there are 10 boxes. """ # Step 1: Compute box scores box_scores = box_confidence * box_class_probs
# Step 2: Find the box_classes thanks to the max box_scores, keep track of the corresponding score box_classes = K.argmax(box_scores, axis = -1) # axis = -1 指的是从反向取值,在这里相当于 axis = 3 box_class_scores = K.max(box_scores, axis = -1) # Step 3: Create a filtering mask based on "box_class_scores" by using "threshold". The mask should have the # same dimension as box_class_scores, and be True for the boxes you want to keep (with probability >= threshold) filtering_mask = box_class_scores >= threshold # Step 4: Apply the mask to scores, boxes and classes scores = tf.boolean_mask(box_class_scores, filtering_mask) # tf.boolean_mask:如果第一个参数维度为 N,那么第二个mask 参数维度K必须小于等于N,返回的值维度为 N-K+1 boxes = tf.boolean_mask(boxes, filtering_mask) # 所以这里用 19*19*5 的 mask 筛选 19*19*5 的向量,最后返回的维度是 1,即(?,),?是因为不知道多少box被选出来 classes = tf.boolean_mask(box_classes, filtering_mask) # 所有选出来的 box 被展开在一个一维向量里 return scores, boxes, classes
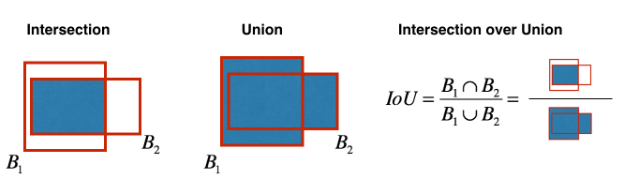
defiou(box1, box2): """Implement the intersection over union (IoU) between box1 and box2 Arguments: box1 -- first box, list object with coordinates (x1, y1, x2, y2) box2 -- second box, list object with coordinates (x1, y1, x2, y2) """ # Calculate the (y1, x1, y2, x2) coordinates of the intersection of box1 and box2. Calculate its Area. xi1 = max(box1[0], box2[0]) yi1 = max(box1[1], box2[1]) xi2 = min(box1[2], box2[2]) yi2 = min(box1[3], box2[3]) inter_area = (xi2 - xi1) * (yi2 - yi1)
# Calculate the Union area by using Formula: Union(A,B) = A + B - Inter(A,B) box1_area = (box1[2] - box1[0]) * (box1[3] - box1[1]) box2_area = (box2[2] - box2[0]) * (box2[3] - box2[1]) union_area = box1_area + box2_area - inter_area # compute the IoU iou = inter_area / union_area return iou
# 非最大值抑制 defyolo_non_max_suppression(scores, boxes, classes, max_boxes = 10, iou_threshold = 0.5): """ Applies Non-max suppression (NMS) to set of boxes Arguments: scores -- tensor of shape (None,), output of yolo_filter_boxes() boxes -- tensor of shape (None, 4), output of yolo_filter_boxes() that have been scaled to the image size (see later) classes -- tensor of shape (None,), output of yolo_filter_boxes() max_boxes -- integer, maximum number of predicted boxes you'd like iou_threshold -- real value, "intersection over union" threshold used for NMS filtering Returns: scores -- tensor of shape (, None), predicted score for each box boxes -- tensor of shape (4, None), predicted box coordinates classes -- tensor of shape (, None), predicted class for each box Note: The "None" dimension of the output tensors has obviously to be less than max_boxes. Note also that this function will transpose the shapes of scores, boxes, classes. This is made for convenience. """ max_boxes_tensor = K.variable(max_boxes, dtype='int32') # tensor to be used in tf.image.non_max_suppression() K.get_session().run(tf.variables_initializer([max_boxes_tensor])) # initialize variable max_boxes_tensor # Use tf.image.non_max_suppression() to get the list of indices corresponding to boxes you keep nms_indices = tf.image.non_max_suppression(boxes, scores, max_boxes, iou_threshold) # 返回一个一维的索引值向量,形状为 (?,) ,表示那些最后被留下来的方框的索引值
# Use K.gather() to select only nms_indices from scores, boxes and classes scores = K.gather(scores, nms_indices) # 根据索引值取出对应的方框的值 boxes = K.gather(boxes, nms_indices) classes = K.gather(classes, nms_indices) return scores, boxes, classes
defyolo_eval(yolo_outputs, image_shape = (720., 1280.), max_boxes=10, score_threshold=.6, iou_threshold=.5): """ Converts the output of YOLO encoding (a lot of boxes) to your predicted boxes along with their scores, box coordinates and classes. Arguments: yolo_outputs -- output of the encoding model (for image_shape of (608, 608, 3)), contains 4 tensors: box_confidence: tensor of shape (None, 19, 19, 5, 1) box_xy: tensor of shape (None, 19, 19, 5, 2) box_wh: tensor of shape (None, 19, 19, 5, 2) box_class_probs: tensor of shape (None, 19, 19, 5, 80) image_shape -- tensor of shape (2,) containing the input shape, in this notebook we use (608., 608.) (has to be float32 dtype) max_boxes -- integer, maximum number of predicted boxes you'd like score_threshold -- real value, if [ highest class probability score < threshold], then get rid of the corresponding box iou_threshold -- real value, "intersection over union" threshold used for NMS filtering Returns: scores -- tensor of shape (None, ), predicted score for each box boxes -- tensor of shape (None, 4), predicted box coordinates classes -- tensor of shape (None,), predicted class for each box """ # Retrieve outputs of the YOLO model box_confidence, box_xy, box_wh, box_class_probs = yolo_outputs
# Convert boxes to be ready for filtering functions boxes = yolo_boxes_to_corners(box_xy, box_wh)
# Use one of the functions you've implemented to perform Score-filtering with a threshold of score_threshold (≈1 line) scores, boxes, classes = yolo_filter_boxes(box_confidence, boxes, box_class_probs, score_threshold) # Scale boxes back to original image shape. boxes = scale_boxes(boxes, image_shape)
# Use one of the functions you've implemented to perform Non-max suppression with a threshold of iou_threshold (≈1 line) scores, boxes, classes = yolo_non_max_suppression(scores, boxes, classes, max_boxes, iou_threshold) return scores, boxes, classes
总结
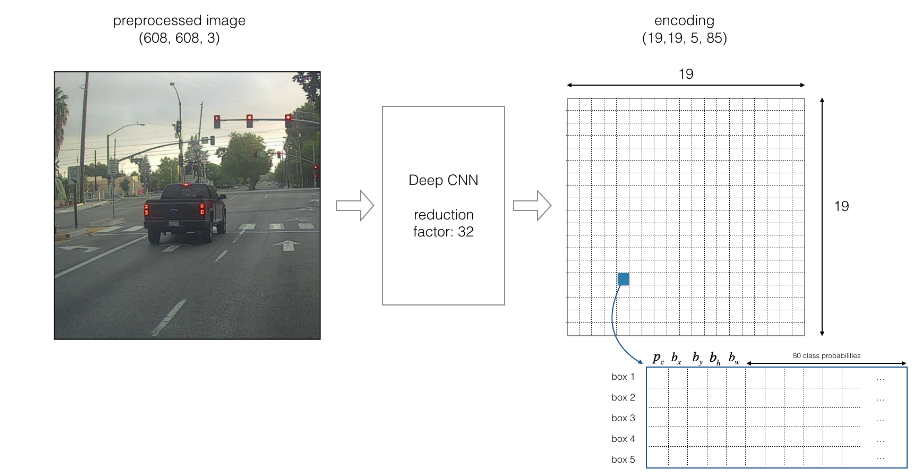
Input image (608, 608, 3)
The input image goes through a CNN, resulting in a (19,19,5,85) dimensional output.
After flattening the last two dimensions, the output is a volume of shape (19, 19, 425):
Each cell in a 19x19 grid over the input image gives 425 numbers.
425 = 5 x 85 because each cell contains predictions for 5 boxes, corresponding to 5 anchor boxes, as seen in lecture.
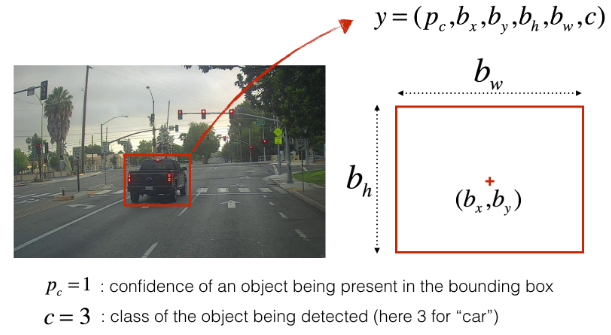
85 = 5 + 80 where 5 is because $(p_c, b_x, b_y, b_h, b_w)$ has 5 numbers, and and 80 is the number of classes we’d like to detect
You then select only few boxes based on:
Score-thresholding: throw away boxes that have detected a class with a score less than the threshold
Non-max suppression: Compute the Intersection over Union and avoid selecting overlapping boxes
defyolo_head(feats, anchors, num_classes): """Convert final layer features to bounding box parameters. Parameters ---------- feats : tensor Final convolutional layer features. anchors : array-like Anchor box widths and heights. num_classes : int Number of target classes. Returns ------- box_xy : tensor x, y box predictions adjusted by spatial location in conv layer. box_wh : tensor w, h box predictions adjusted by anchors and conv spatial resolution. box_conf : tensor Probability estimate for whether each box contains any object. box_class_pred : tensor Probability distribution estimate for each box over class labels. """ num_anchors = len(anchors) # Reshape to batch, height, width, num_anchors, box_params. anchors_tensor = K.reshape(K.variable(anchors), [1, 1, 1, num_anchors, 2]) # Static implementation for fixed models. # TODO: Remove or add option for static implementation. # _, conv_height, conv_width, _ = K.int_shape(feats) # conv_dims = K.variable([conv_width, conv_height])
# Dynamic implementation of conv dims for fully convolutional model. conv_dims = K.shape(feats)[1:3] # assuming channels last # In YOLO the height index is the inner most iteration. conv_height_index = K.arange(0, stop=conv_dims[0]) conv_width_index = K.arange(0, stop=conv_dims[1]) conv_height_index = K.tile(conv_height_index, [conv_dims[1]])
# Adjust preditions to each spatial grid point and anchor size. # Note: YOLO iterates over height index before width index. box_xy = (box_xy + conv_index) / conv_dims box_wh = box_wh * anchors_tensor / conv_dims
defpredict(sess, image_file): """ Runs the graph stored in "sess" to predict boxes for "image_file". Prints and plots the preditions. Arguments: sess -- your tensorflow/Keras session containing the YOLO graph image_file -- name of an image stored in the "images" folder. Returns: out_scores -- tensor of shape (None, ), scores of the predicted boxes out_boxes -- tensor of shape (None, 4), coordinates of the predicted boxes out_classes -- tensor of shape (None, ), class index of the predicted boxes Note: "None" actually represents the number of predicted boxes, it varies between 0 and max_boxes. """
# Run the session with the correct tensors and choose the correct placeholders in the feed_dict. # You'll need to use feed_dict={yolo_model.input: ... , K.learning_phase(): 0}) out_scores, out_boxes, out_classes = sess.run([scores, boxes, classes], feed_dict={yolo_model.input:image_data, K.learning_phase(): 0})
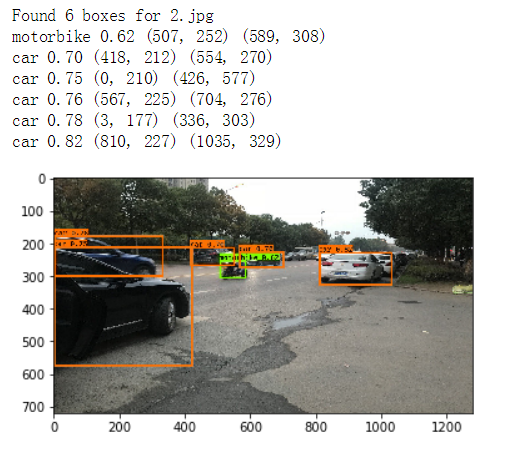
# Print predictions info print('Found {} boxes for {}'.format(len(out_boxes), image_file)) # Generate colors for drawing bounding boxes. colors = generate_colors(class_names) # Draw bounding boxes on the image file draw_boxes(image, out_scores, out_boxes, out_classes, class_names, colors) # Save the predicted bounding box on the image image.save(os.path.join("out", image_file), quality=90) # Display the results in the notebook output_image = scipy.misc.imread(os.path.join("out", image_file)) imshow(output_image) return out_scores, out_boxes, out_classes
YOLO is a state-of-the-art object detection model that is fast and accurate
It runs an input image through a CNN which outputs a 19x19x5x85 dimensional volume.
The encoding can be seen as a grid where each of the 19x19 cells contains information about 5 boxes.
You filter through all the boxes using non-max suppression. Specifically:
Score thresholding on the probability of detecting a class to keep only accurate (high probability) boxes
Intersection over Union (IoU) thresholding to eliminate overlapping boxes
Because training a YOLO model from randomly initialized weights is non-trivial and requires a large dataset as well as lot of computation, we used previously trained model parameters in this exercise. If you wish, you can also try fine-tuning the YOLO model with your own dataset, though this would be a fairly non-trivial exercise.