
本周主要学习如何通过 CNN 来进行物体检测。
物体定位(单个物体)
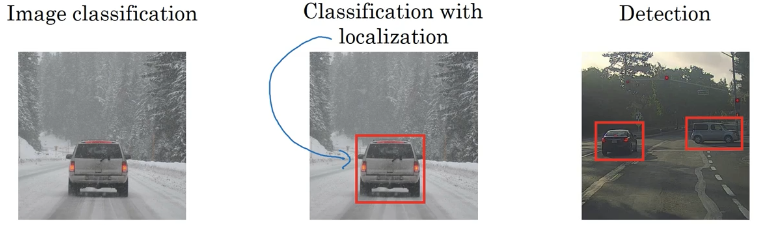
什么是物体定位
- 图像分类:图片中是否有车
- 物体定位:不仅要识别出是否有车(单个对象),还要在车的周围生成一个边框,即分类+定位
- 物体检测:找到一张图片里的多个对象并定位它们
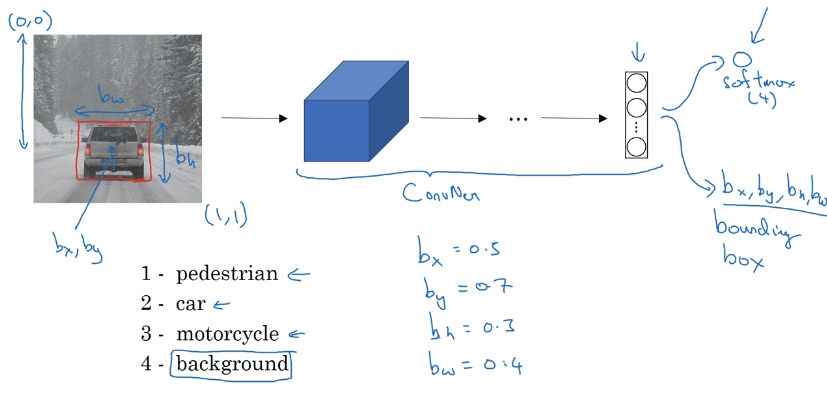
如何定位
假设我们需要找出图片中是否有以下四类对象:
- 行人
- 车
- 摩托车
- 无物体
我们最后用 softmax 输出四个分类,不仅如此,为了找出它们的位置,还需要输出以下四个值:
- $b_x$ :方框中心的横坐标
- $b_y$:方框中心的纵坐标
- $b_h$:方框的高度
- $b_w$:方框的宽度
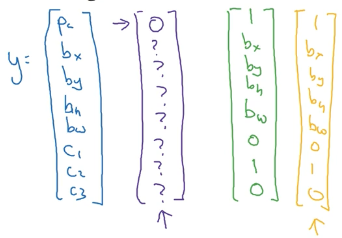
最后目标标签为:
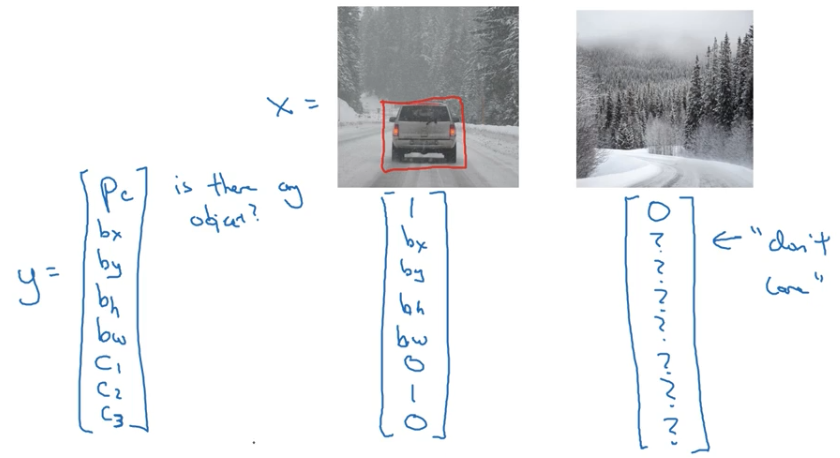
- Pc 指的是图片中存在该单个对象的概率,若有则值为 1,若没有则值为 0
- C1、C2、C3 当物体为某个类时,对应的 C 值取 1,其他取 0
- 当 Pc 为 0 时,也就是图片中不存在物体时,剩下的 ? 值表示我们并不关心这些值是多少
损失函数
假设使用平方误差,那么:
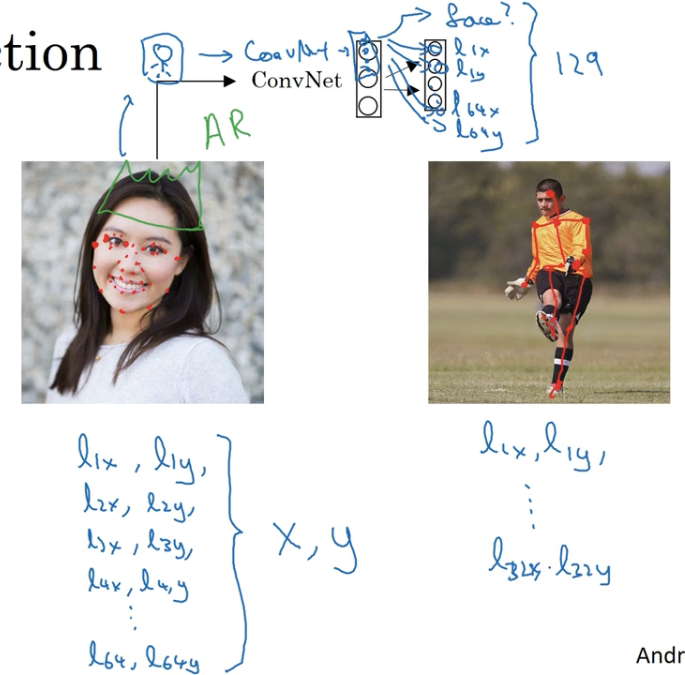
特征点检测
当我们需要找出图片中的一些特征点时,我们可以在标签中增加这些点的坐标。
例如我们需要识别出下面这张脸的五官的轮廓,我们可以定义一些特征点,产生含有这些特征点坐标的训练集,然后我们将图片丢进神经网络,最后输出若干个值。
物体检测(多个物体)
滑动窗口检测法 Sliding Windows
拍一张照片然后裁剪掉其他不是汽车的部分,得到一张汽车剧中并几乎占全部画面的紧密裁剪的汽车图像,使用许多紧密裁剪的汽车图像作为训练集,训练一个神经网络判断是车。

在一张可能包含汽车的大图像中,先选择一个窗口尺寸,然后只读取这个小窗口内的图像,输入到上面训练的卷积网络中,做一个预测,滑动窗口检测指的是将小窗口按步长移动到下一个位置,再重复上述操作,再移动窗口,重复上述操作,直到滑动窗口遍历了图像中的所有位置。

然后我们可以取不同大小的窗口重复上述操作,只要图像某处中有一辆车,那么就会有某个窗口会圈住一辆车然后检测出来。

缺点:
- 当你使用较大的窗口移动步长,算法表现会下降
- 当你使用较小的步长,计算成本则会非常高
滑动窗口检测的卷积实现
如果每个小窗口的图像都通过这么一个卷积网络:

我们将全连接层改造成以下的结构,实现参数共享,减少计算量:
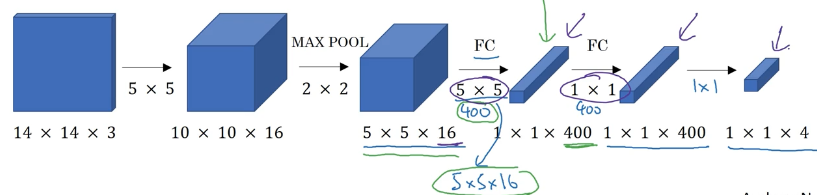
具体做法是:
我们将待检测的大图像直接输入到我们改造后的(本来用来预测窗口图像的)卷积网络中,最后的输出就是我们对应的每个滑动窗口的结果,而不是一个窗口一个窗口滑动,截取图像然后输入。
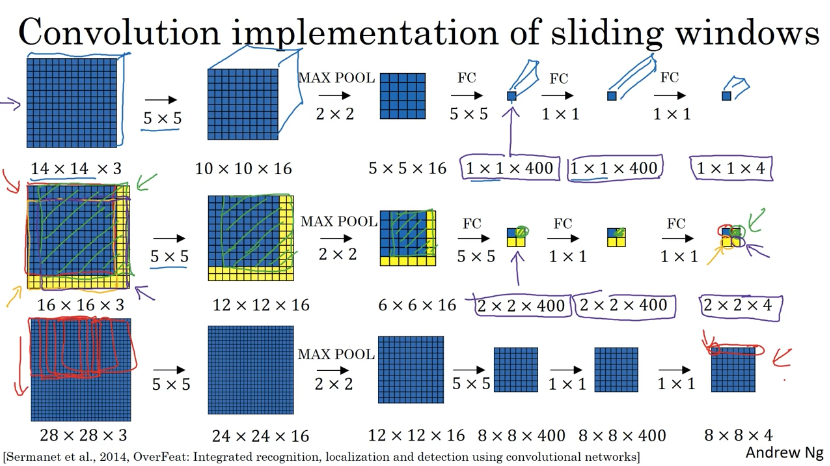
由于直接将整个图像输入到训练好的网络,在同一时间将所有的滑动窗口实现了前向传播,实现了参数的共享,减少了计算的成本。
缺点:由于窗口只能是正方形,所以边界框的位置不准确。
边界框预测
YOLO 算法介绍
为了更好地检测出物体的真实边界,可以使用 YOLO 算法,是 you only look once 的缩写。
有一张图片,首先用 9×9 的网络划分(当然实际使用中可以使用更加精细的),然后将开始学到的物体定位算法运用在这每一个网格中。
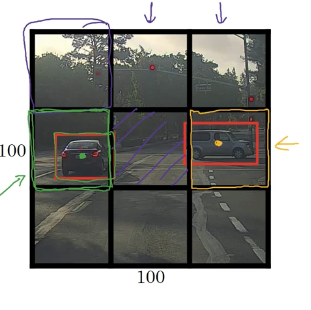
那么根据每个网格是否有物体,如果有,那么边界框坐标是多少,是什么类别,得到每个网格的标签值 y 为:
值得注意的是,每个物体就算跨越了多个网格,我们也只能将其划分到它中心点所在的网格里。
所以最后将这些标签堆叠起来形成一个维度为 3×3×8 的标签(8 指的是每个网格的 8 个标签值)。
我们要做的是输入训练集进入一个卷积网络,我们通过调整网络超参数使得最后输出一个 3×3×8 的向量,这就与我们 3×3×8 的标签形成对应,构造代价函数。经过训练之后,我们随便输入一张图像,就可以知道在网格每个位置是否存在物体,对应的边界框坐标是什么。
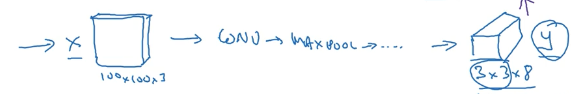
如何确定边界框的参数
一种方法是令网格的左上角为(0,0),右下角为(1,1),那么中心点的坐标由它相对(0,0)的位置决定,一定介于 0~1 之间;而方框的长跟宽根据它和网格宽度的比例决定,可以超过 1.
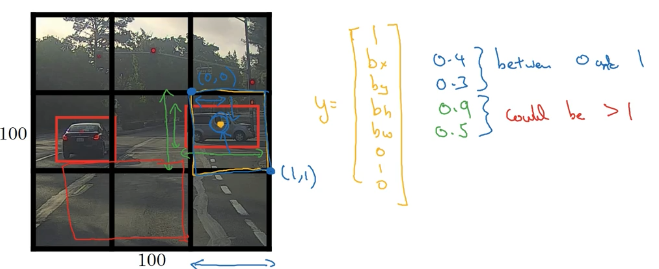
例如上面黄色中心点的坐标约为(0.4,0.3,0.9,0.5)。
如何评价物体检测算法
为了知道物体检测算法的性能好坏,可以使用一个叫做“交并比 (Intersection Over Union)”的函数.
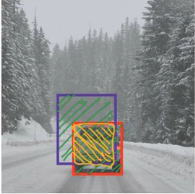
假设红框是实际的边界,紫框是算法预测的边界,黄色部分是两者的交集,绿色部分是两者的并集,那么:
交并比 IoU = 交集的面积 / 并集的面积。
判别:一般来说,如果 IoU 大于等于 0.5,便可认为定位正确。也可以定义更严格的值。
非最大值抑制 non-max suppression
如下图所示,一个 19×19 的网格将图片划分,运行 YOLO 算法,可能对于一辆汽车,有许多网格都认为该汽车的中心点在它那里,即这辆汽车的范围内的许多网格都认为自己检测到了汽车了,发生重复检测的问题。抑制非最大值可以确保算法对一个物体只检测一次,而不是检测许多次。

如果一辆车检测了许多次,就会在其周围产生许多方框,如下图所示,每个方框上的数字表示该网格认为自己检测到了物体的概率:
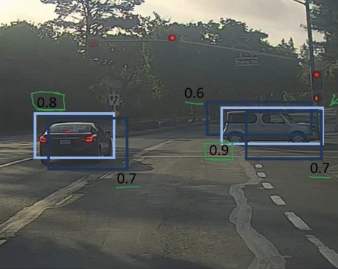
抑制非最大值的具体的做法为(假设只是检测单一物体):
- 每个网格的输出为:$\begin{bmatrix}
p_c\\
b_x\\
b_y\\
b_h\\
b_w\\
\end{bmatrix}$ - 丢弃所有低概率网格,例如 $p_c \leqslant 0.6$ (或其他概率)的网格
- 在剩下的网格中
- 挑选出具有最大 $p_c$ 值的网格
- 丢弃那些与刚刚选出的网格的方框的 IoU 值大于 0.5 的网格(如果 IoU 大于某个阈值,这说明这两个方框重合度太高,便认为它们识别的是同一个物体)
- 在剩下的网格中重复上述操作
如果检测是多种物体,比如汽车、行人、摩托车,那么正确的做法是:各自独立,进行三次“抑制非最大值”。
实际中的使用方法见下方的“非最大值抑制”。
锚框法 anchor boxes
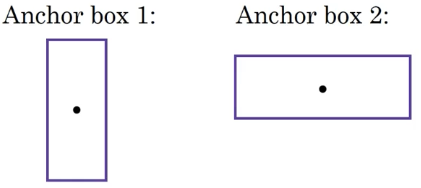
目前看过的物件检测算法,有一个问题是每一个网格只能侦测一个物件,如果一个网格想要侦测多个物体,可以使用“锚框法 anchor boxes”。

对于上面这张图,我们发现人和汽车的中心点几乎重叠在一起,在一个格子里,如果输出 $y = \left[ \begin{array} { c } { p _ { c } } \\ { b _ { x } } \\ { b _ { y } } \\ { b _ { w } } \\ { b _ { w } } \\ { c _ { 1 } } \\ { c _ { 2 } \\ c_3 } \end{array} \right]$,那么它无法同时输出两个物体的方框,只能二选一,我们可以在这个网格画出两个锚框(也可能更多)框住这两个物体,如下图所示:
然后将输出的标签改为:
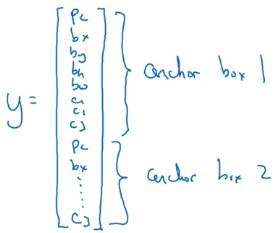
用锚框 1 来框住行人,锚框 2 来框住汽车。
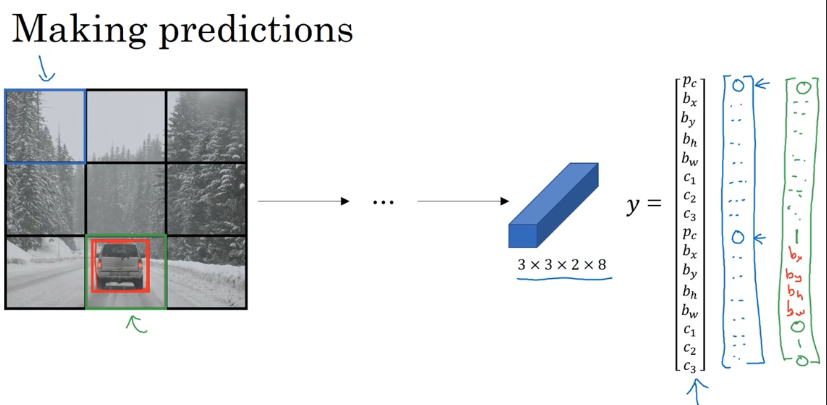
在使用锚框前:训练图片中的每个物体被分给一个包含了它中心点的格子。输出维度 3×3×8。
使用锚框后:训练图片中的每个物体被分给(1)包含了它中心点的格子(2)这个格子里据有更高 IoU 的锚框。输出维度为 3×3×2×8。
举个例子:
标签值 $y=\left[ \begin{array} { l } { p _ { c } } \\ { b _ { x } } \\ { b _ { y } } \\ { b _ { h } } \\ { b _ { w } } \\ { c_ { 1 } } \\ { c _ { 2 } }\\ { c _ { 3 } } \\ { p _ { c } } \\ { b _ { x } } \\ { b _ { y } } \\ { b _ { h } } \\ { b _ { w } } \\ { c _ { 1 } } \\ { c _ { 2 } } \\ { c _ { 3 } } \end{array} \right]$,假如某个网格有两个物体,则为 $ \left[ \begin{array} { l } { 1 } \\ { b _ { x } } \\ { b _ { y } } \\ { b _ { h } } \\ { b _ { w } } \\ { 1 } \\ { 0}\\ { 0 } \\ { 1 } \\ { b _ { x } } \\ { b _ { y } } \\ { b _ { h } } \\ { b _ { w } } \\ { 0 } \\ { 1 } \\ { 0 } \end{array} \right] $,如果只有车,则为 $ \left[ \begin{array} { l } { 0 } \\ { ? } \\ { ?} \\ { ? } \\ { ? } \\ { ?} \\ { ?}\\ { ? } \\ { 1 } \\ { b _ { x } } \\ { b _ { y } } \\ { b _ { h } } \\ { b _ { w } } \\ { 0 } \\ { 1 } \\ { 0 } \end{array} \right] $
实际上,在一个网格处理两个物体的情况很少发生,尤其是当网格为 19×19 时。
YOLO 物体检测算法
综合上面所有要素,来组成目前最先进的目标检测算法——YOLO 算法。
构建训练集并训练
- 三个分类类别:行人、汽车、摩托车
- 两个锚框
- 3×3 的网格划分(实际中一般是 19×19)
- 遍历每张图片的 9 个网格,得到标签向量,维度是 3×3×2×8
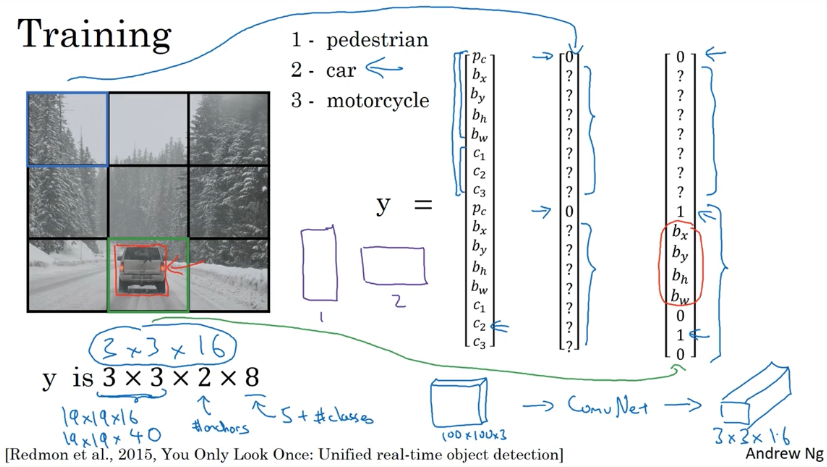
进行预测
非最大值抑制
每个网格都会得到两个预测的边界框(因为有两个锚框)

计算每个方框的“分数”,如下图所示:
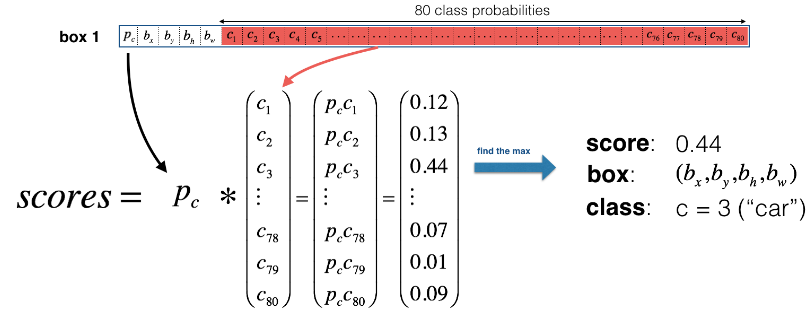
去掉所有分数低于某个阈值的方框

在剩下的方框中,对于分类的每个类别(行人、汽车、摩托车等),单独对每个预测的类别执行非最大值抑制
- 挑选出分数最大的方框
- 丢弃那些与刚刚分数最大方框的 IoU 值大于 0.5(或其他阈值) 的网格
- 如果 IoU 大于某个阈值,这说明这两个方框重合度太高,便认为它们识别的是同一个物体
- 在除了分数最大方框的剩下的方框中,找出分数最大的,重复上述操作
- 直到没有更低分数的方框存在,停止迭代,得到最终的预测框


