
本周我们直接从研究论文里学习深度 CNN 的一些使用技巧和方法。
outline
一些经典的网络模型:
- LeNet-5
- AlexNet
- VGGNet
残差卷积网络 ResNet
- 初始神经网络实例
经典卷积网络模型
LeNet-5

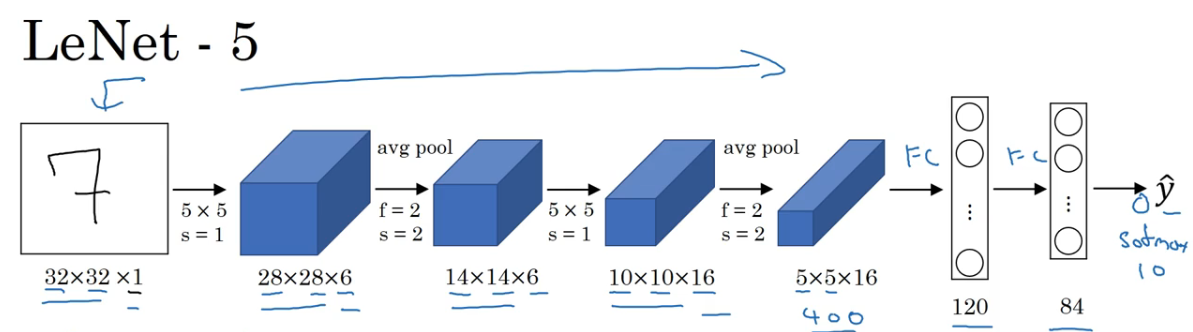
- 60000 个参数
- 从左到右 $n_H,n_W$ 减小,$n_C$ 增大
- 一个至今使用的模式:conv -> pool -> conv -> pool -> FC -> FC -> output
- 这篇论文中使用的是 sigmoid/tanh 函数,而不是 ReLU
- 由于论文较久远,吴恩达建议只读论文的第二章,快速看一下第三章
AlexNet
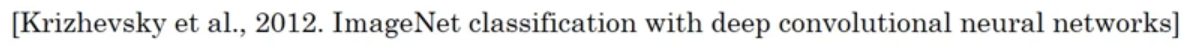
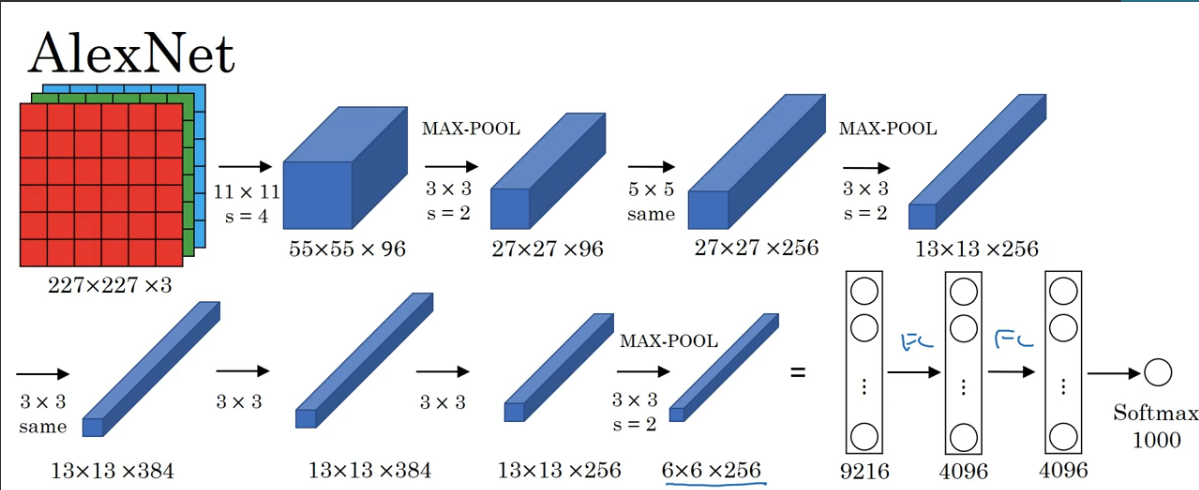
- 与 LetNet 很相似,但是大得多,大概六千万个参数
- 使用 ReLU 激活函数
- 使用两块 GPU 训练
- 局部响应归一层 LRN
VGG-16

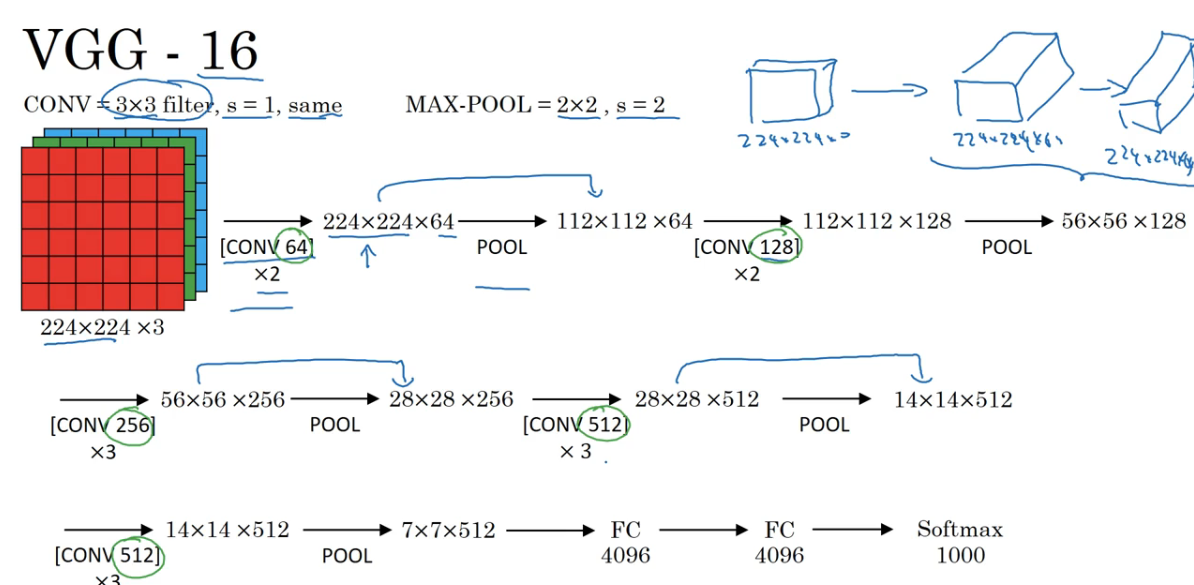
- 超过一亿三千万个参数,十分庞大的网络
- 结构非常统一,缺点是网络过于庞大
建议先读 AlexNet 的论文,再读 VGG-16 的论文,最后读最难的 LeNet。
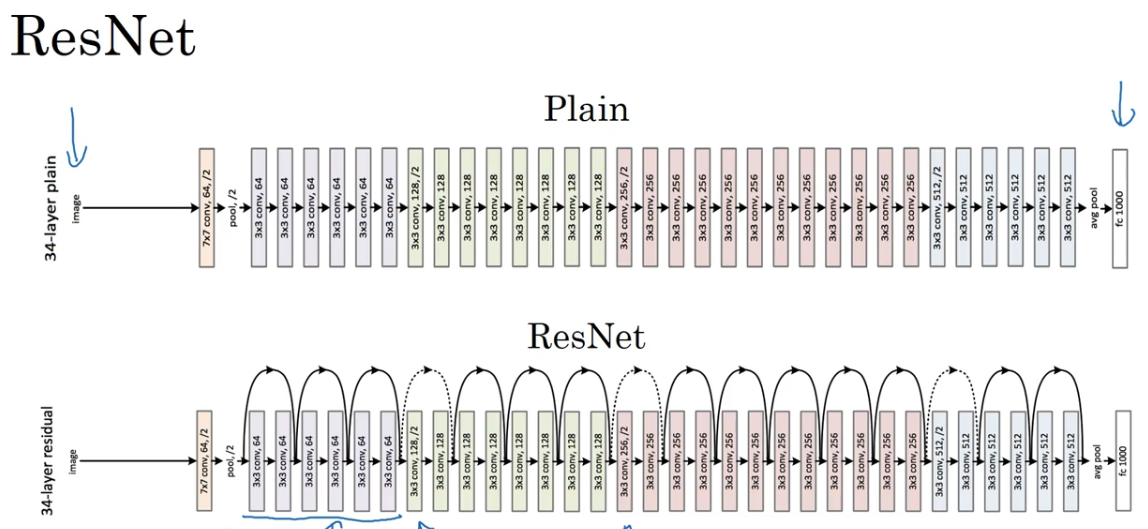
残差网络 ResNet
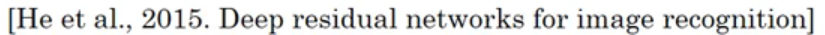
训练网络很深时会发生梯度消失或者梯度爆炸,利用“跳跃连接” ( skip connection),可以训练很深很深的残差网络。
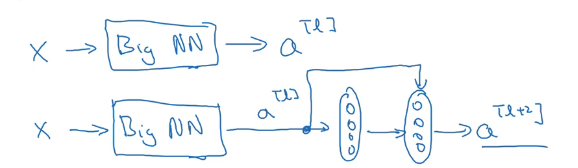
残差结构 residual block
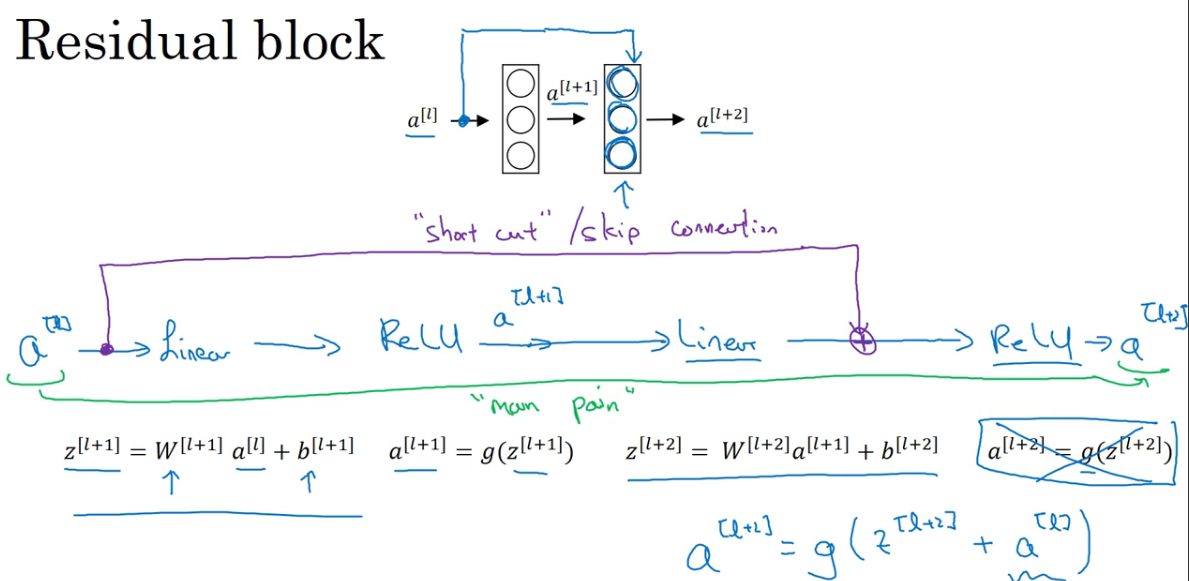
- 绿色的叫主路径 (main path)
- 紫色的叫快捷路径 (short cut) 或 跳跃连接 (skip connection)
- 最后两者合一得到的 $a^{[l+1]} = g(z^{[l+2]}+a^{[l]})$
残差网络 Residual Network
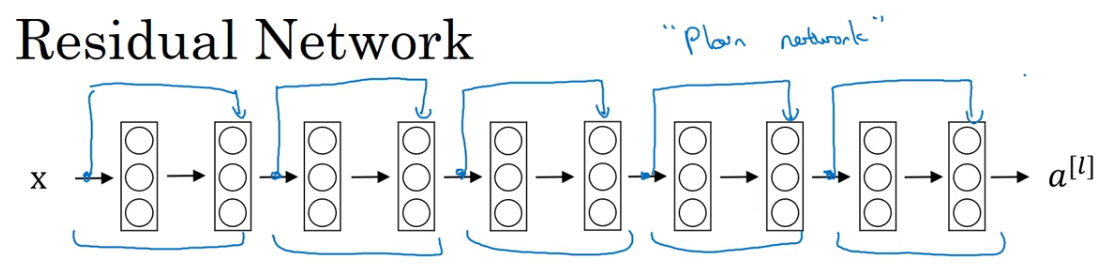
性能对比
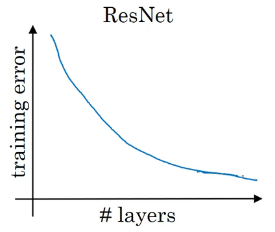
对于一个普通网络 (plain network),随着层数的增大,理论上训练误差应该减小,但是实际上是先减小后增大,如下图所示。
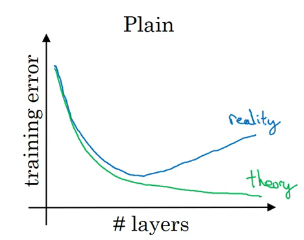
而如果使用 ResNet,即使训练一个 1000 层的网络,性能也不会先增后降。
为什么 ResNet 有用
假设我们在一个网络后面加上一个残差结构,如下图所示。
所有的激活函数使用的都是 ReLU,所以 $a \geq 0 $
$a^{[l+2]}=g(z^{[l+2]}+a^{[l]})=g(w^{[l+2]}a^{[l+1]}+b^{[l+2]}+a^{[l]})$
加入使用正则化使权重衰减,w 和 b 变得很小,如果没有残差结构,那么可能会发生梯度消失,但是如果有残差结构,那么就算 w 和 b 衰减到 0,$a^{[l+2]}=g(a^{[l]})=ReLU(a^{[l]})=a^{[l]}$,所以额外增加两层也不会损害神经网络的表现。
要实现跳跃连接,我们必须假设 $z^{[l+2]}$ 和 $a^{[l]}$ 是同维度,这样才能相加,所以深度残差网络里面很多 same 卷积,保证卷积之后维度不变。
但是有时候 $z^{[l+2]}$ 和 $a^{[l]}$ 维度不同,比如 256 和 128,我们可以加上一个系数 $W_S$:
$a^{[l+2]}=g(w^{[l+2]}a^{[l+1]}+b^{[l+2]}+W_sa^{[l]})$
此处$W_S$ 是一个 256×128 的矩阵。
Inception 网络
1*1 卷积

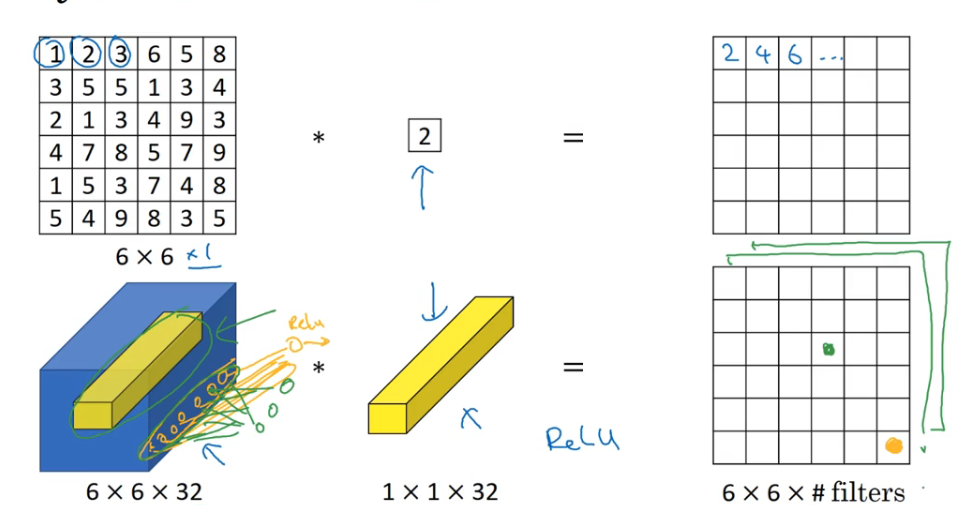
1×1 卷积本质上就是一个全连接神经网络,逐一作用于这 6×6=36 个不同的位置,这个小神经网络接收一行 32 个数的输入,然后输出过滤器数个输出值。这个有时被称作“网中网”。
一个实例:
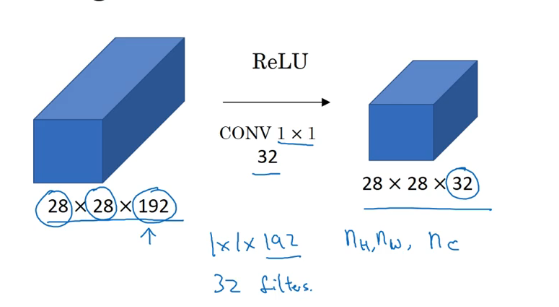
我们可以用 1×1 卷积来缩小通道数:
Inception network 引例
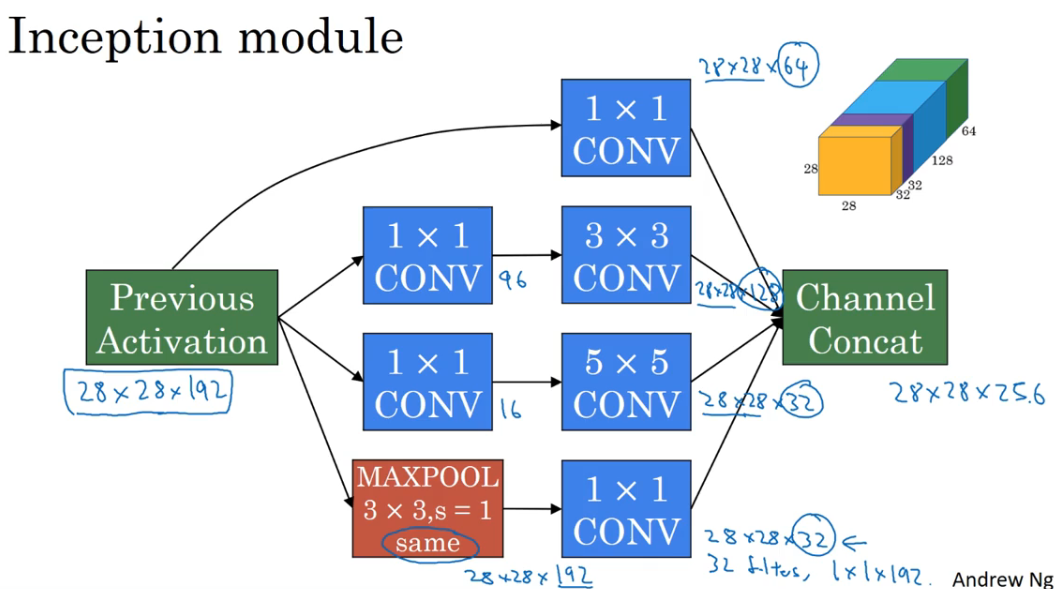
在设计卷积网络的某一层的时候,有可能会用到1×1的卷积层或者3×3的卷积层或者5×5的卷积层或者池化层,Inception 网络在某一层将这些全部用上,使得网络更复杂,效果也更好。
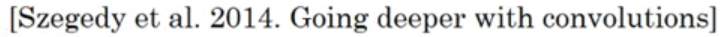
我们将输出进行不同的卷积操作,但是都进行 “same padding”,使得输出维度都一样,最后将所有的输出堆叠起来,这就形成了 Inception 网络的一个模块。
计算成本问题
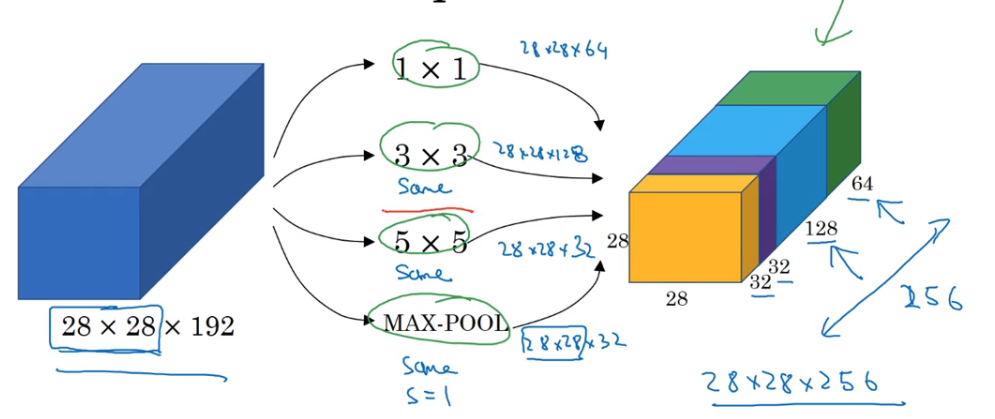
我们看 5×5 的卷积核。
像上图一样直接将 5×5 的卷积核与 28×28×192 的输入进行卷积,得到 28×28×32 的输出
最后进行的乘法运算次数为 28×28×32×5×5×192 约等于 1.2亿 次
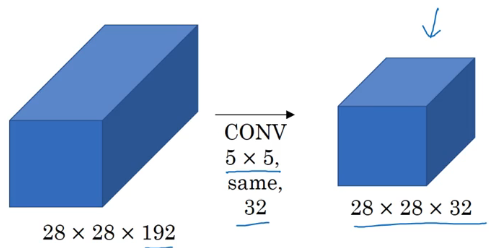
在进行 5×5 卷积之前进行一个 1×1 卷积(瓶颈层),先将通道数减到 16,再进行 5×5 卷积,得到 28×28×32 的输出
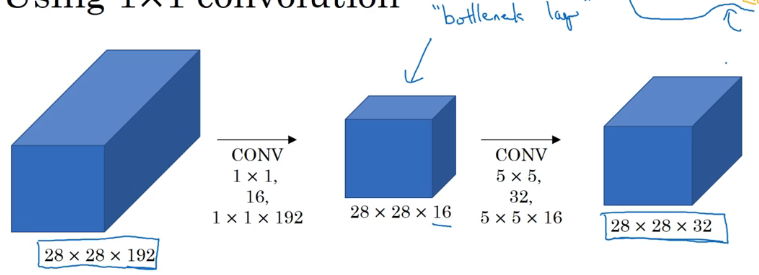
最后的运算次数为 28×28×16×192×1×1 + 28×28×32×5×5×16 约为 1240万 次,是第一种方法的十分之一运算量。
Inception 模块
Inception 网络
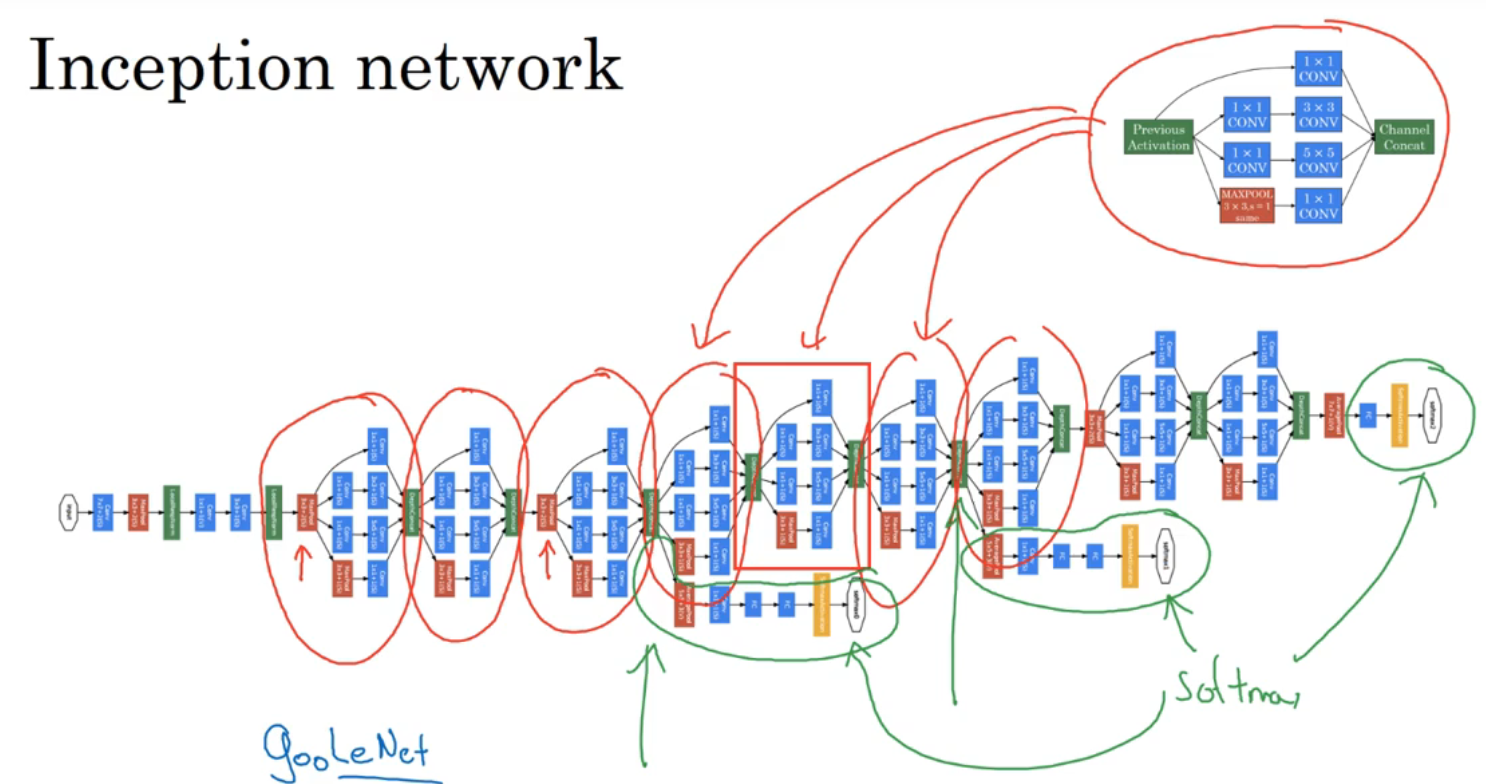
红色部分是一个一个 Inception 模块
绿色的旁支是以隐藏层作为输入的 softmax 函数,防止网络太深了过拟合
这个网络是谷歌开发的 gooleNet,用来纪念 Lecun 的 LeNet
Inception 这个名字来源于《盗梦空间 (Inception)》表情包:),作者们把这个图片当成了构建更加有深度的神经网络的动机:

搭建卷积网络的小技巧
使用开源资源
- 使用文献中的网络结构
- 使用开源的网络结构算法实现
- 使用人家预训练好的模型然后在自己的数据集上进行微调
迁移学习
如果你想实现一个计算机视觉应用而不想从零开始训练权重,实现更快的方式通常是下载已经训练好权重的网络结构,把这个作为预训练迁移到你感兴趣的新任务上,计算机视觉的研究社区已经很擅长把许多数据库发布在网络上,如 ImageNet、MSCOCO、PASCAL 等数据库,许多计算机视觉的研究者已经在上面训练了自己的算法,有时训练要耗费好几周时间,占据许多 GPU,事实上有人已经做过这种训练,这意味着你可以下载这些开源的权重为你自己的神经网络做好的初始化开端,且可以用迁移学习来迁移知识,从这些大型公共数据库迁移知识到你自己的问题上。
假如我们要识别家里的两只猫,训练数据量不够,我们可以从网上下载一些训练好的模型,比如在有 1000 类物体的 ImageNet 数据库上训练的模型。
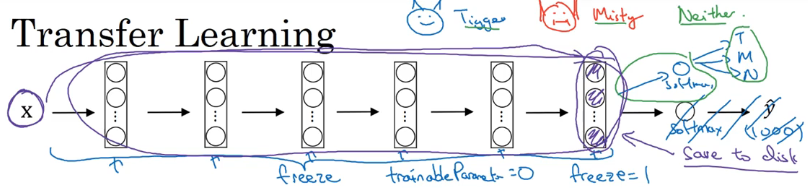
将紫色框住的部分全部“冻结住”,可训练参数为零,将这部分看成一个模块或者函数,我们需要做的是把 1000 分类的 softmax 改成 3 分类的然后训练 softmax 这部分的参数即可。

当你有更大的带标签数据集,你可以冻结更少的层数。只冻结前面这些层,然后训练后面这些层,(1)你可以用最后几层的权重,作为初始化开始做梯度下降,把 softmax 改成自己需要的(2)或者你也可以去掉最后几层,然后用自己的新神经元和新 softmax 输出。原则是:你数据越多,所冻结的层数可以越少,自己训练的层数可以越多。

最后,如果你有许多数据,你可以用该开源网络和权重来初始化整个网络然后训练。
数据增强
在计算机视觉领域,更多的数据对几乎所有的计算机视觉工作都有好处,但是对于绝大多数问题,总是不能获得足够多的数据,这就需要数据增强。
普通数据增强方式
镜像 mirroring
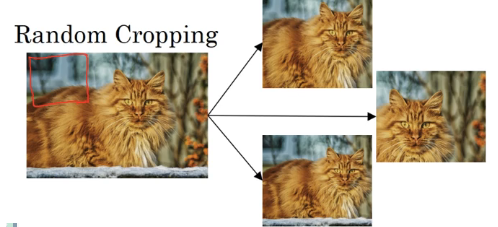
随机裁剪 random cropping
旋转 rotation
剪切 shearing
局部弯曲 local warping
……
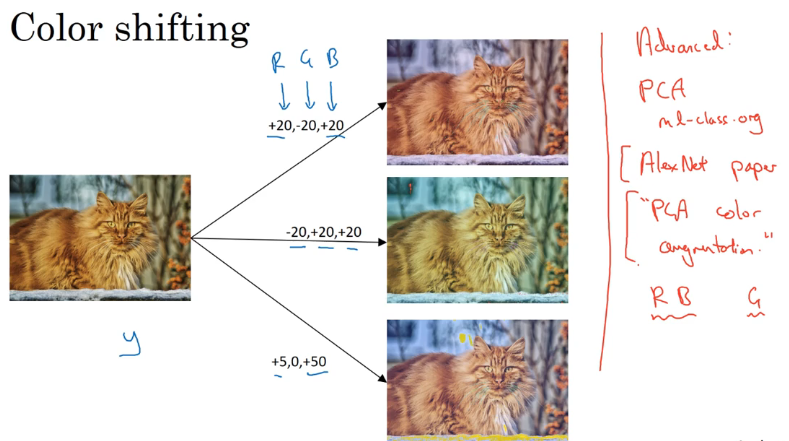
色彩变化 color shifting
给三个颜色通道 R G B 增加不同的值,可以使用 PCA 主成份分析算法来实现。
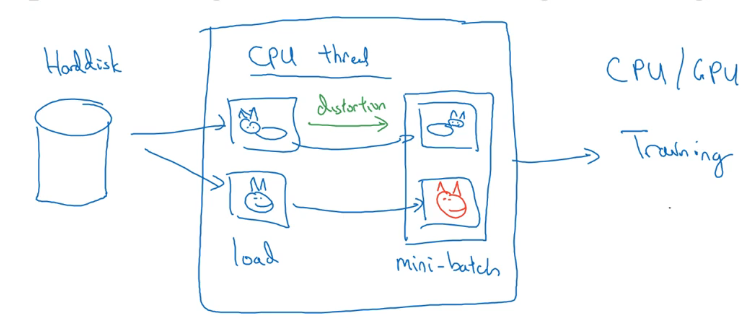
数据增强线程
数据存在硬盘中,在进入 CPU/GPU 训练之前使用几个 CPU 线程进行失真处理(数据增强),训练线程和失真线程可以并行处理。
目前计算机视觉的状态
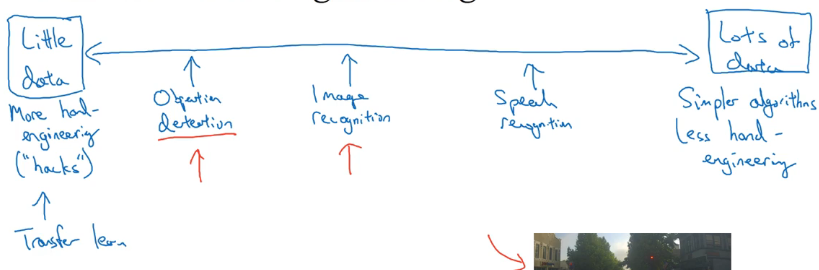
机器学习的两种知识来源:
- 带标签的数据
- 手工构建的 特征/网络结构/其他组件
当我们拥有大量的数据,我们只需要简单的算法和更少的手工构建部分,而当我们数据量不够时,就需要更多的手工构建部分,需要花更多时间在设计网络结构上。传统的计算机视觉论文,相当依赖复杂的手工构建,就算近些年随着数据量的增加,手工构建的数量明显减少,但还是有很多手工设计的网络架构,所以超参数选择在计算机视觉比起其他领域更加复杂。
在基准数据集上做的好 / 赢得比赛 的技巧
这些方法在比赛时可以使得结果准确度增加一些微弱的优势,但是会增加很多运算成本,所以这些东西并不会真的用在实际的服务客户的系统上。
Ensembling 总效果
- 独立训练几个网络然后取输出值的平均值
multi-crop at test time 在测试时多重裁剪
在测试图像的多个裁剪子图像中运行分类器然后求结果平均值


