
计算机视觉
计算机视觉的问题
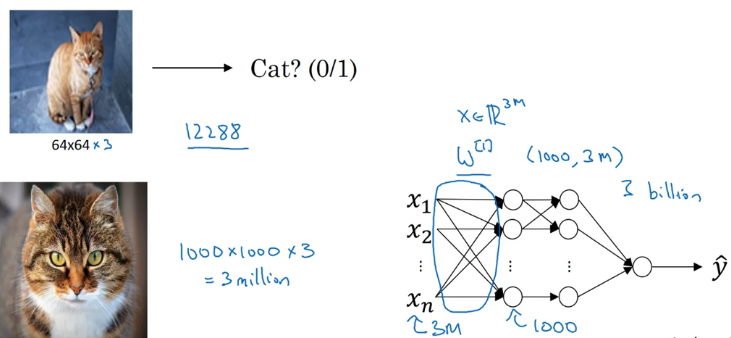
图像分类:例如猫分类器
物体检测:例如自动驾驶不仅需要识别出图片中是否有车,还要计算出这张图片中汽车的位置
神经风格转换:如下图

计算机视觉的挑战
图片的像素可以任意大,输入维度可以任意大,会导致:
- 很难获得足够数据避免过拟合
- 对计算量和内存的需求很大
卷积运算 (Convolutional operation)
引例
假设要检测下图的垂直边缘和水平边缘:
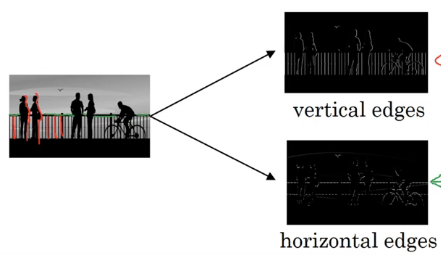
检测垂直边缘可以使用如下方法:
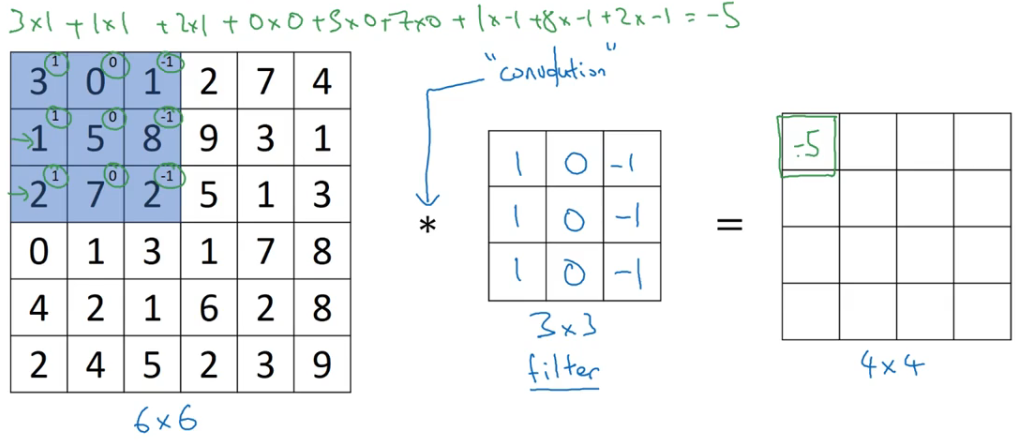
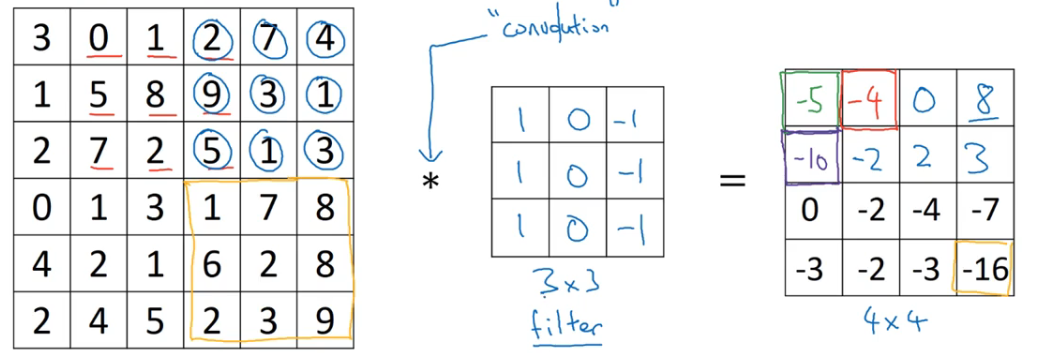
- 左边是某个图像
- 中间是一个 3×3 的过滤器 (fliter),是一个矩阵,有时也称为核 (kernel)
- * 符号表示卷积运算
- 将蓝框中的值逐元素乘以过滤器矩阵的值然后相加得到第一个结果 -5,下面的以此类推
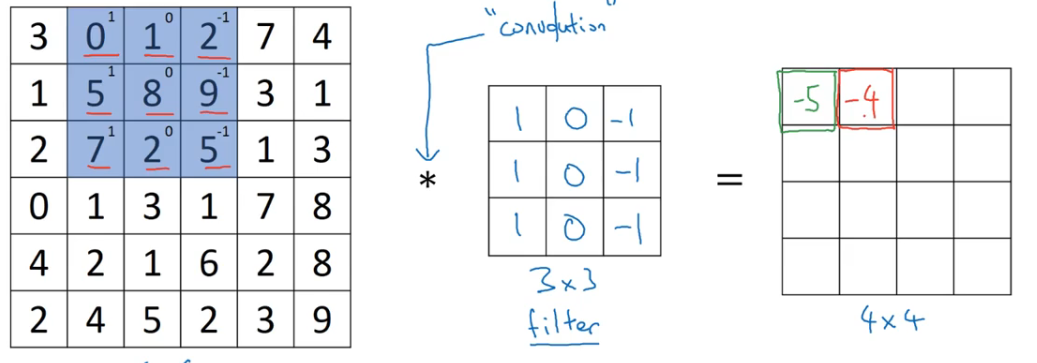
中间的过滤器就是一个垂直边缘检测器,那么它是如何检测边缘的?
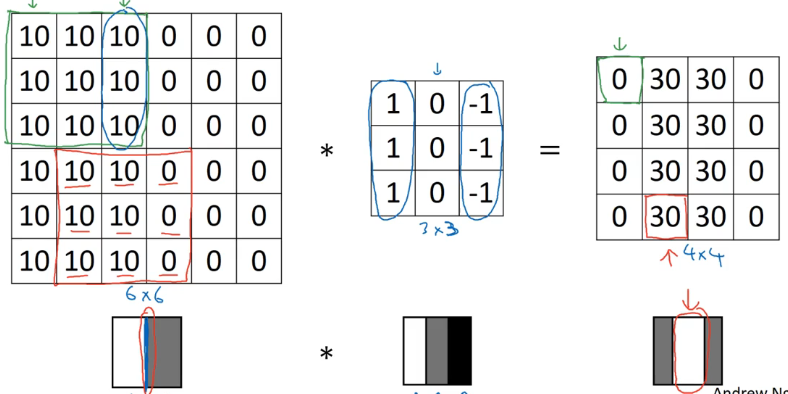
- 边缘左侧像素值大,更明亮,右侧像素值小,更暗,最后得到的结果是更亮的区域在正中间,与检测出的垂直边缘相对应
- 检测出的边缘看起来很厚,是因为使用 6×6 的小图像,如果使用大图像就不会发生这种比例失调
- 过滤器告诉我们一个信息:某个垂直边缘是 3×3 的区域,左边有亮像素,右边有暗像素,而不在意中间有什么,这种区域被认为有垂直边缘
更多边缘检测例子
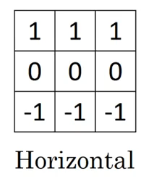
还有许多种精心设计的过滤器,比如水平边缘过滤器:
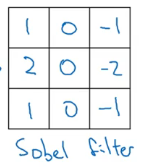
还有 sobel filter:
还有 scharr filter:

随着深度学习的发展我们发现,如果你想要检测一些复杂图片的边界,可能并不需要计算机视觉的研究人员挑选出这 9 个矩阵元素。你可以把矩阵里的这 9 个元素当做参数,通过反向传播来学习得到他们的数值,它能学到比前述这些人为定义的过滤器更加善于捕捉你的数据的统计学特征的过滤器。除了垂直和水平边界,同样能够学习去检测 45 度的边界 70 度 或 73 度,无论什么角度。
填充 (paddling)
卷积运算的一些问题
如果我们用 3×3 的过滤器去卷积 6×6 的图像,最后得到的是一个 4×4 的图像,这样会出现两个问题:
- 输出的图像逐渐缩小,如果网络的层数很深,那么许多层之后会得到一个非常小的图片
- 角落上的像素值只会在输出中被使用一次,而中间的像素会重叠许多次,导致丢失了图片靠近边界上的信息
怎麽办
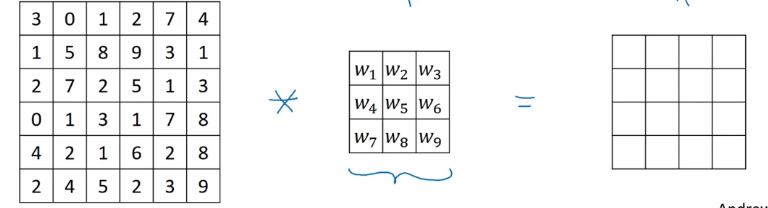
为了消除这两个问题,可以在卷积前用一个额外的边缘 (border) 填充图片,例如我们可以在 6×6 的图片边缘用一个 1 像素大小的额外边缘,那么这个图片就变成 8×8,和 3×3 的过滤器卷积之后得到一个 6×6 的图片,和原来尺寸一样,如下图所示。
- 填充的边缘厚度为 p,上图中 p = 1
到底填充多少?——两种卷积
valid 卷积 —— 没有填充
same 卷积 —— 填充后使得输入大小等于输出大小
- 其中 p 为填充的厚度,f 为过滤器的边长
- 当 f 为奇数时,p 按照上面公式取值即可以使得输入输出相同
- 一般实际中 f 都是使用奇数,有如下两个原因:
- 如果 f 是偶数,则需要一些不对称填充
- 奇数过滤器可以有个中心点,称之为中心像素,可以描绘过滤器的位置
带步长的 (strided) 卷积
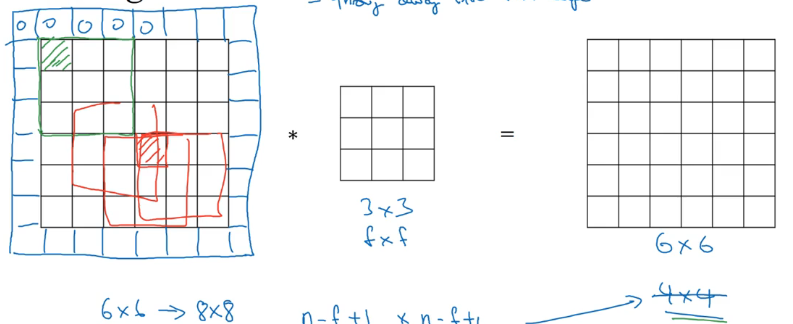
在卷积时过滤器移动的步长不为 1 称为带步长的卷积。如果步长 stride = 2 结果如下图所示。
加入我们有:
- n×n 的图像
- f×f 的过滤器
- 填充 padding 为 p
- 步长 strides 为 s
如果将两者卷积,输出为:

- 其中 [ ] 为向下取整,也就是小于它的最大整数,[z] = floor(z)
一个提法的纠正
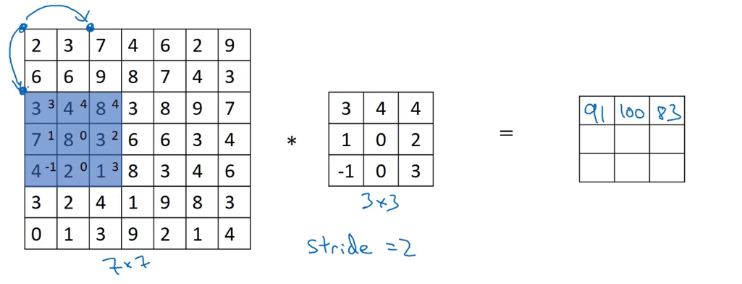
实际上,在正式数学课本中,卷积操作前还需要一个额外的“翻转”操作,即将原来的过滤器先水平翻转再竖直翻转,如下图所示:
而深度学习中的“卷积”操作,将翻转操作取消了,数学上应该叫“交叉相关”,但是大多数深度学习文献都叫它卷积操作。
对三维立方体的卷积
假如我们的图像是 RGB 图像,那么它不是一个二维的灰度图像,而是一个 6×6×3 的三维图像,其中 3 为图像的通道数,这种图像如何卷积呢?
单过滤器
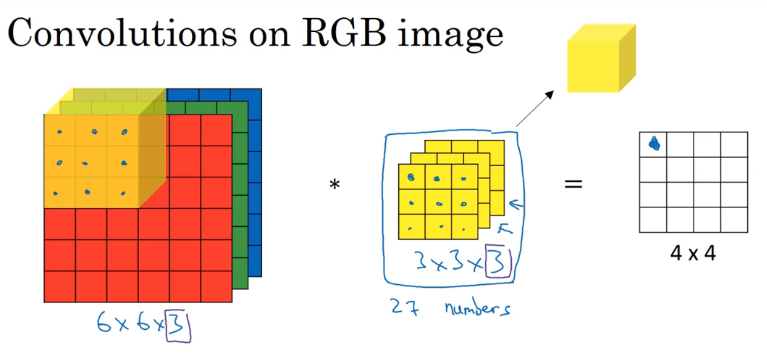
- 3 为图像的通道数,图像的通道数应该和过滤器的通道数一致
- 将每一层的过滤器的 9 个数字与对应通道的图像像素值相乘,最后把这所有的 27 个数字相加得到第一个输出,其他的以此类推
多过滤器
如果我们希望检测多个边缘,那么可以使用多个过滤器。
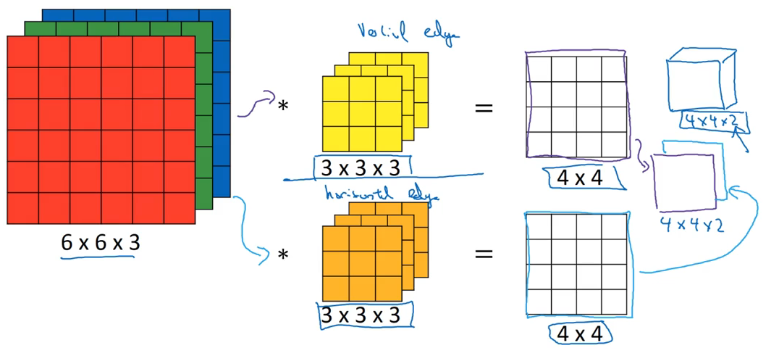
总结:
其中 $n_c$ 为图像通道数,图像通道数应该和过滤器一致
- 有时候 $n_c$ 称之为三维立方体的深度
其中 $n_c’$ 为过滤器的数量,即检测的特征数量
现在我们不仅可以直接处理拥有 3 个通道的 RGB 图片,而且更重要的是,可以检测两个特征,比如垂直、水平边缘,或者 10 个,128 个,甚至几百个不同的特征。
单层卷积神经网络
引例
下面是一个卷积层的计算过程。
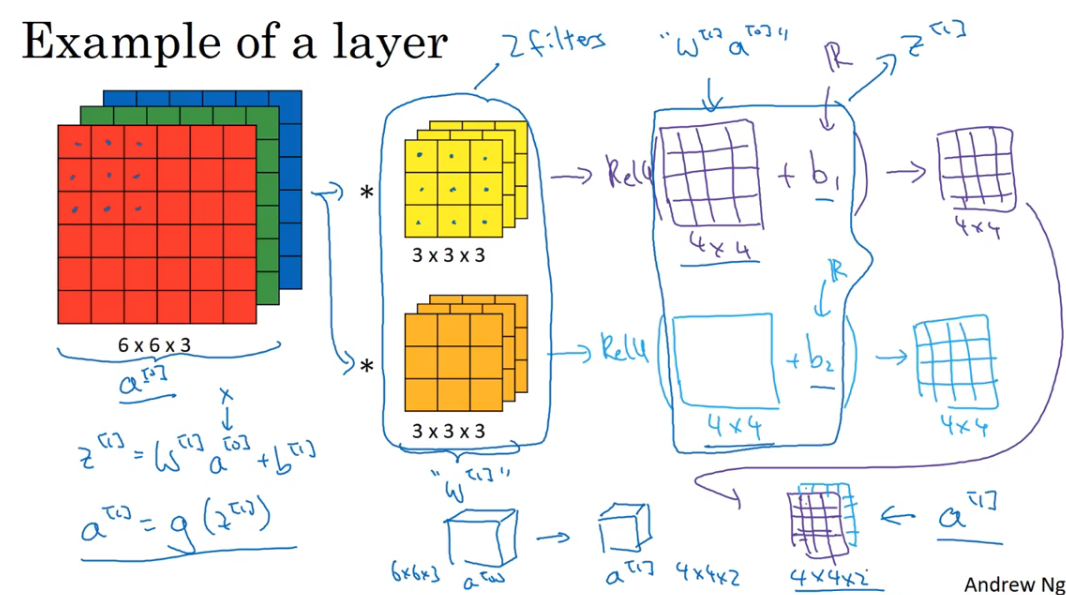
- 假设输入图像为一个 6×6×3 的 $a^{[0]}$,那么输出为 4×4×2 的 $a^{[1]}$
- 其中过滤器相当于参数 $w^{[1]}$,第二个蓝框里相当于 $z^{[1]}$,经过激活函数 Relu 之后变为 $a^{[1]}$
一层卷积层的参数
假设你有 10 个 3×3×3 的过滤器在一层神经网络中,那么这一层有多少个参数?
parameters = ( 3×3×3 +1 ) × 10 = 280 个
这是一个很好的特性:不管输入的图像有多大,比方 1000 x 1000 或者 5000 x 5000,这里的参数个数不变. 依然是 280 个。因此 用这 10 个过滤器来检测一个图片的不同的特征,比方垂直边缘线,水平边缘线或者其他不同的特征,不管图片多大,所用的参数个数都是一样的。
标记符号总结
如果第 $l$ 层是一个卷积层:
- 过滤器尺寸:$f^{[l]}$
- 填充厚度:$p^{[l]}$
- 卷积步长:$s^{[l]}$
- 过滤器数量:$n_c^{[l]}$
- 输入:$n_H^{[l-1]} \times n_W^{[l-1]} \times n_c^{[l-1]}$
- 其中 H 代表高度,W 代表宽度,C 代表通道 channel
- 输出:$n_H^{[l]} \times n_W^{[l]} \times n_c^{[l]}$
- $n_H^{[l]}=[\frac{n_H^{[l-1]}+2p^{[l]}-f^{[l]}}{s^{[l]}}+1]$,$n_W^{[l]}=[\frac{n_W^{[l-1]}+2p^{[l]}-f^{[l]}}{s^{[l]}}+1]$
- 其中 $[ \ ]$ 为向下取整
- $n_H^{[l]}=[\frac{n_H^{[l-1]}+2p^{[l]}-f^{[l]}}{s^{[l]}}+1]$,$n_W^{[l]}=[\frac{n_W^{[l-1]}+2p^{[l]}-f^{[l]}}{s^{[l]}}+1]$
- 每个过滤器为:$f^{[l]} \times f^{[l]} \times n_c^{[l-1]}$ (注意不是 $n_c^{[l]}$)
- 这一层的激活值:$a^{[l]} \rightarrow n_H^{[l]} \times n_W^{[l]} \times n_c^{[l]}$
- 向量化激活值:$ A^{[l]} \rightarrow m \times n_H^{[l]} \times n_W^{[l]} \times n_c^{[l]}$
- 权重:$f^{[l]} \times f^{[l]} \times n_c^{[l-1]} \times n_c^{[l]}$
- 其中 $n_c^{[l]}$ 为 $l$ 层的过滤器数量
- 偏差:$1 \times 1 \times 1 \times n_c^{[l]}$
深层卷积神经网络
引例
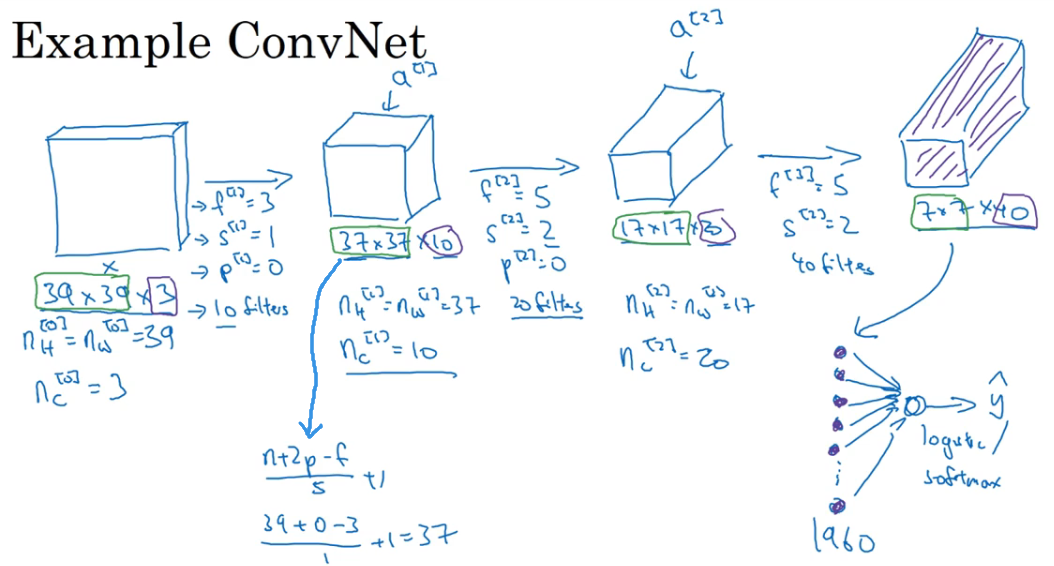
- 最后我们得到一个 7×7×40 的激活值,一共 1960 个数展开为一个列向量,然后输入到一个逻辑回归或者 softmax 单元得到预测值
卷积网络中的层类型
- 卷积层 Convolution Layers (简称 Conv)
- 池化层 Pooling Layers (简称 Pool)
- 全连接层 Fully connected Layers (简称 FC)
池化层 (Pooling Layers)
Max pooling 最大值采样
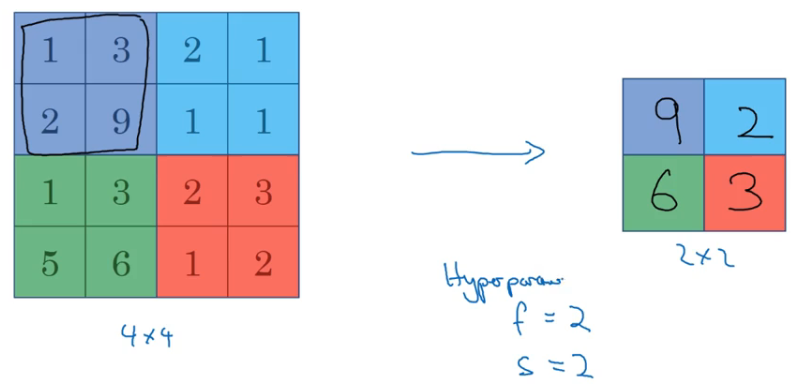
- Max pooling 和卷积操作基本一样,只是最后输出的是滤波器范围内的最大值
- 如果你把这个 4x4 的区域看作某个特征的集合,那么一个大的数字就意味着它或许检测到了一个特定的特征,所以左侧上方的四分之一区域有这样的特征,它或许是一个垂直的边沿 亦或一个更高或更弱,但是右侧上方的四分之一区域没有这个特征。所以 max pooling 做的是检测到所有地方的特征,四个特征中的一个被保留在 max pooling 的输出中。
Average pooling 平均值采样

- 平均值采样输出的是滤波器范围内所有值的平均值
- 不如 max pooling 常用
总结:
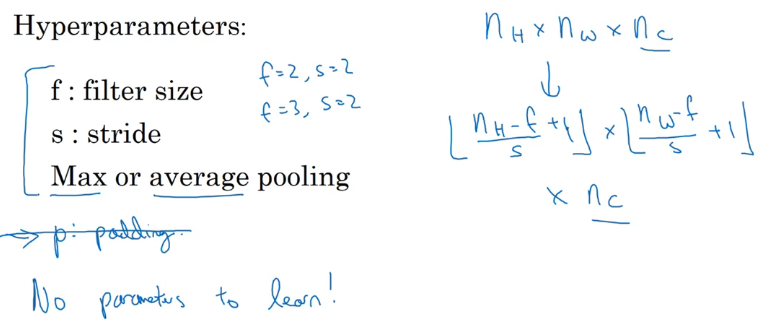
池化层没有任何参数要学习!是确定的函数!
识别手写数字的例子
下面是一个用来识别手写数字的神经网络:
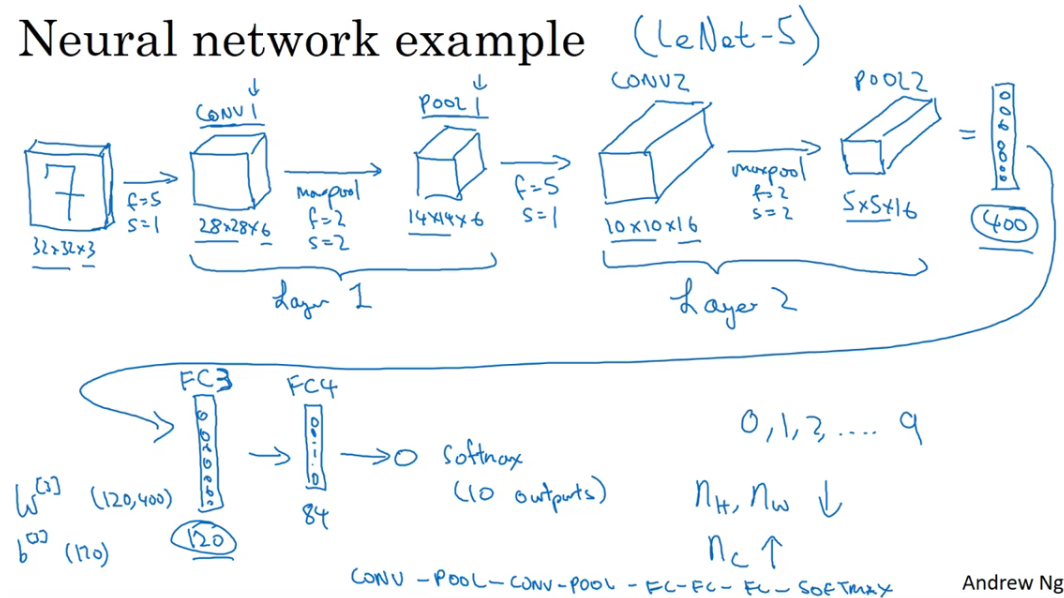
- conv 是 卷积层,pool 是池化层,FC 是全连接层
- 由于池化层没有权重和参数,所以不把它算作一个独立的层,而是视 conv1 和 pool1 为 layer 1,但是在某些文献中把卷积层和池化层视为两个独立的层
总结:
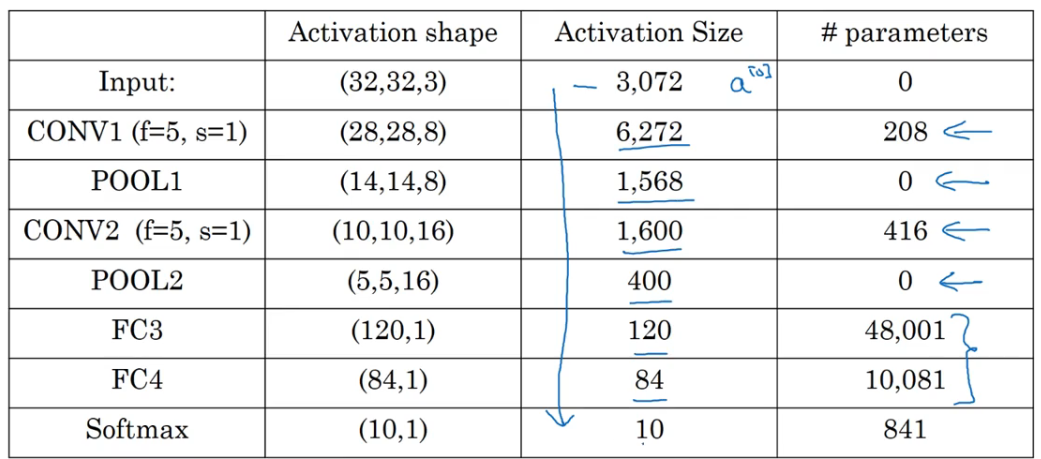
- 池化层没有参数
- 卷积层趋向于拥有越来越少的参数
为什么卷积如此有用
- 参数共享: 在特征检测器中(例如垂直边缘检测)对于图像的一部分是有用的,那么对于另一部分可能也是有用的。
- 连接的稀疏性:在每一层中,每个输出值只依靠一小部分输出值。也就是说每个输出值都只依赖于滤波器覆盖到的那几个数字,而剩下的像素值对它没有影响。

