
现在来到 coursera 的 deeplearning.ai 课程的第三课,这门课程叫 Structuring Machine Learning Projects 结构化机器学习项目,将会学习到构建机器学习项目的一些策略和基本套路,防止南辕北辙。
正交化 (Orthogonalization)
何为正交化
如同老式电视机一样,一个旋钮控制一个确定的功能,如屏幕横向伸长或纵向伸长,而不会一个旋钮控制两个属性。
ML 的正交化
我们希望某个旋钮能单独让下面的某个步骤运行良好而不影响其他,这就叫正交化。
- 首先训练集要拟合的很好
- 否则减小偏差
- 如果训练集运行良好,则希望开发集运行良好
- 否则减小方差
- 如果在训练集和开发集运行良好,则希望在测试集运行良好
- 否则采用更大的开发集
- 最后希望在真实世界表现良好
- 否则调整开发集或者改变代价函数
当你发现某个步骤表现不好的时候,找到一个特定的旋钮进行调节,从而解决问题。
设置目标
设置单一化的评估指标
- 精确率 precision:模型识别出是猫的集合中,有多少百分比真正是猫
- 召回率 recall:对于全部是猫的图片有多少能正确识别出来

A、B 分类器分别有两个指标 P 和 R,各有长处,不好判断,于是可以计算它们的调和平均数,变成一个单一指标 F1 score,公式为:
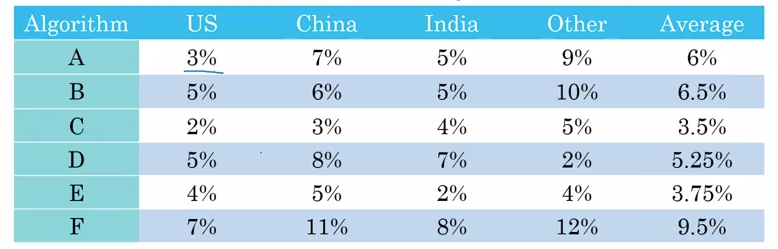
再比如我们知道各个算法在不同国家的错误率,我们求这些错误率的平均值,得到一个单一指标,从而知道 C 算法性能最好。
优化指标和满足指标
优化指标 optimizing metric:指这个指标越大(越小)越好,需要它表现得尽可能好,一般一个问题只需要一个优化指标,其他的是满足指标。
满足指标 satisficing metric:不需要尽可能好,只需要到达某个门槛即可,只要到达了这个门槛就不关心它的值到底是多少。
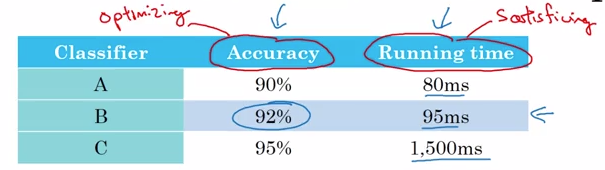
上图中的精确度指标是优化指标,运行时间是满足指标,假设我们设置门槛为 100ms,则首先淘汰 C 分类器,然后由于 B 的优化指标更好,我们需要精确度越大越好,所以最好的分类器是 B,也就是说我们要选出运行时间在 100ms 以内且精确度最大的分类器。
开发集和测试集的设置
指导原则
- 开发集给我们树立了一个靶子,选择的开发集和测试集要能够反映出将来需要预测的数据和你认为重要的数据
- 开发集和测试集应该来自相同的分布
- 训练集和开发集可以来自不同的分布
设定开发集和评估方法就像放置一个目标,然后团队通过各种尝试接近这个目标,使得模型在这个开发集和评估方法上做得更好。如果开发集和测试集来自不同的地方,当你的团队花了几个月靠拢开发集,最后用测试集做测试时,会发现表现并不好。就像让你的团队用数个月的时间瞄准一个目标,但是数个月后你说:“等等,我要测试一下,我要换个目标!”
假设现在有来自世界八个地区的数据,如果将其中四个地区的数据作为 dev sets,另外四个地区的数据作为 test sets,是完全错误的,会导致开发集和测试集的数据分布不同,正确的做法应该是将所有地区的数据混合再分成开发集和测试集,保证数据分布相同。
总结:找到将来你需要的预测的数据,同时放入开发集和测试集中,瞄准你需要的目标。
数据划分比例
- 几百到上万个样本:训练集/测试集=70/30;训练集/开发集/测试集=60/20/20
- 上百万个样本:训练集/开发集/测试集=98/1/1
- 假如一百万个样本,拿一万当开发集,一万当测试集即可
- 测试集有时候可以用开发集代替,但是有测试集会更安心,而且需要足够大才能有足够的自信来评估整个模型表现
什么时候重新定义指标
当你的算法由于某些特殊情况影响了用户体验或者说用户有特殊的需要时
例如我们设置指标为:开发集上猫咪分类的错误率越低越好。算法 A 错误率:3%;算法 B 错误率:5%;根据我们的原有指标来看,明显算法 A 更好。但是现在算法 A 会在推荐猫咪图片时,错误地推荐一些色情图片,这对用户来说是无法忍受的,而 B 算法就不会,所以这种情况下,我们的评估指标发生了变化,B 算法更符合我们的需要。
那么如何修改评价指标?
- $m_{dev}$ 为开发集的个数
- $y_{predict}^{(i)}$ 为第 i 个样本的预测值,取值为 1 或 0
- $I\{y_{predict}^{(i)} \neq y^{(i)} \}$ 如果括号里为真,则值为 1,即错误数加 1
- 如果某个图片是色情图片,则权重 w=10, 将会给它产生更大的误差值,也就是说假如一个图片是色情图片,则它相当于十个错误图片,会大大提高错误率
- $\frac{1}{\sum\limits_iw^{(i)}}$ 是归一化操作,使得 error 介于 0~1 之间
实际情况发生了变化而当前的算法无法满足实际需要时
例如你用网上找到十分精美的图片用作训练集和开发集,来开发猫咪识别算法,但是用户使用时上传各种各样的图片,可能取景不好,可能猫没照全,可能图像模糊,也就是说实际情况发生了改变,我们的目标也发生了改变,这个时候你需要从实际情况获取更多的数据,开始修改你的指标或者开发/测试集了,让它们实际中做得更好。
机器学习的两个正交化步骤
- 立靶子:讨论如何定义一个指标来评估分类器
- 射靶子:如何很好地满足这个指标
与人类表现相比较
为什么要和人类表现相比较
- 机器学习算法快速发展,慢慢在某些领域变得和人类相比有竞争力
- 在某些领域,机器学习效率比人类更高
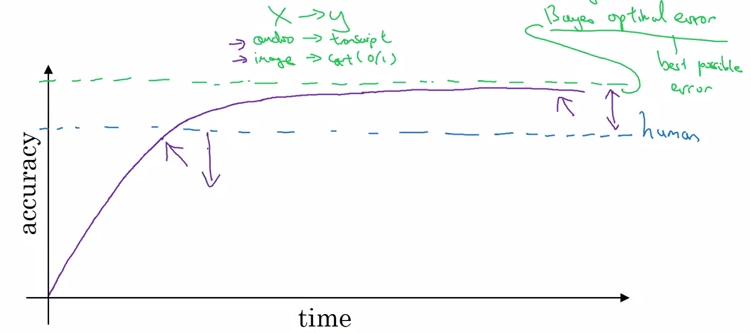
绿线指贝叶斯误差 (Bayers error),它指从 x 映射到 y 的最好的理论函数,永远无法超越,不管是人类还是机器。
当机器的表现超越人类之后进展放慢,原因有:
- 人类的误差在许多任务中与贝叶斯误差相差不远,超越人类之后没有那么大改善空间
- 当表现超越人类之后,就没有什么工具来进行提高了
当机器的表现不如人类,我们可以用以下工具来进行提高:
- 从人类得到标签进行学习
- 人类可以对偏差进行分析,改进算法
- 可以得到更好的偏差/方差分析,即得到一个改进的标准
用人类标准评估偏差
方法:用人类的误差的最低值作为贝叶斯误差的一个估计值。

第一个例子训练集误差跟人类误差差距较大,故专注于减小偏差,第二个例子开发集误差跟训练集误差差距更大,所以专注于减小方差。吴恩达把训练集上的误差和人类误差之间的差值称之为“可回避的偏差”,也就是偏差的下限。所以左边的例子可回避偏差为 7%,右边的为 0.5%,左边的偏差可提高空间很大。
更好地定义“人类表现”
假设看一张 x 光片,不同的人类误差如下:
- 普通人:3%
- 普通医生:1%
- 有经验的医生:0.7%
- 一个有经验的医生团队讨论:0.5% $\rightarrow$ 作为贝叶斯误差的估计值
那么如何定义人类表现呢?搞清楚你的目的:
- 如果是为了超过一个普通人的水平,那么将人类表现定为 1%
- 如果目的是作为贝叶斯误差的代替,那么定义为 0.5% 更好
举个例子:
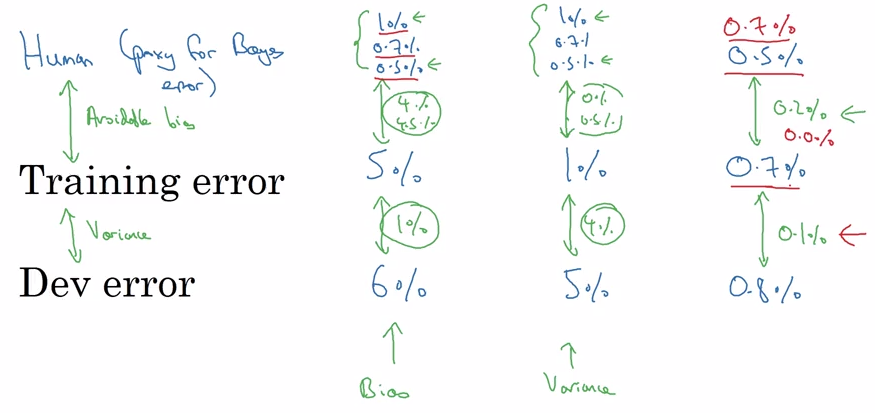
第一种情况,无论人类表现定义为哪种,可避免偏差都很大,所以专注于减小偏差,第种,无论人类表现定义为哪种,都专注于减小方差,第三种情况由于训练集误差只有 0.7%,所以人类表现的最好定义是 0.5%。
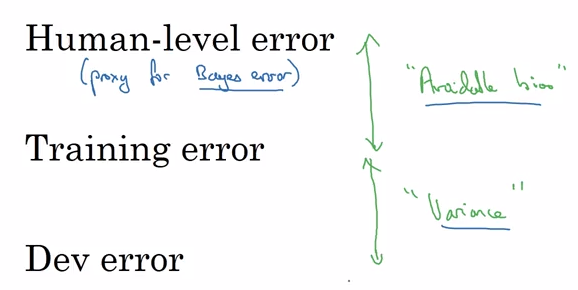
总之:人类误差(贝叶斯误差的估计值)和训练集误差之间的的差距代表了可避免的偏差,训练集误差和开发集误差之间的差距代表了方差。
ML 明显超过人类的领域
- 在线广告
- 产品推荐
- 物流(预测运输时间)
- 贷款批准
- 某些医学领域
- 某些语音识别
- 某些图像识别
人类更擅长的是自然感知任务,包括视觉,语音识别,自然语言处理等;机器更适合处理结构化数据相关任务。
如何提高模型表现
- 如何减小可避免偏差
- 训练更大的模型
- 训练更久/更高的优化算法
- 动量算法、RMSprop、Adam
- 改变神经网络结构/超参数搜寻
- 使用 RNN/CNN
- 如何减小方差
- 更多数据
- 正则化
- L2、dropout、数据集增强
- 改变神经网络架构/超参数搜寻

