
本次作业实现了几种梯度下降算法,比较了它们的不同。
普通梯度下降 (BGD)
所谓普通梯度下降就是一次处理所有的 m 个样本,也叫批量梯度下降 (Batch Gradient Descent),公式为:
1 | def update_parameters_with_gd(parameters, grads, learning_rate): |
随机梯度下降 Stochastic Gradient Descent (SGD)
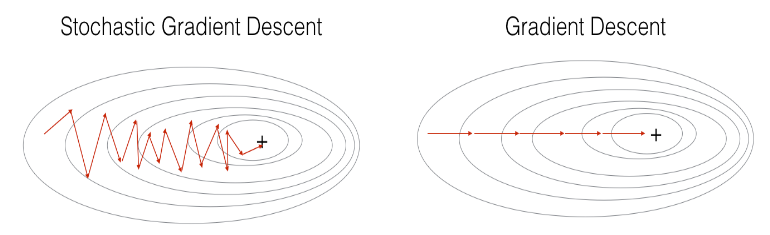
SGD 一个只处理一个样本进行梯度下降,速度比 GD 快,但是在朝着最小值行进的过程中会发生震荡,而 GD 是平滑地稳步向最小值走。GD 是考虑周全再行动,每一步都朝着全局最优走,所以很慢,而 SGD 是走一步看一步,并不是每一步的迭代都朝着全局最优的方向走,噪声很多,如下图所示。
SGD 算法中有三个 for 循环:
- 迭代次数的循环
- 所有 m 个训练样例的循环
- 神经网络所有层的循环
1 | X = data_input |
小批量梯度下降 Mini-Batch Gradient descent (MBGD)
由于 BGD 和 SGD 是两个极端,如果一次既不处理一个样本,也不处理所有样本,而处理介于两者之间的样本数,即一次处理整个训练样本的一小批,学习速度会更快。
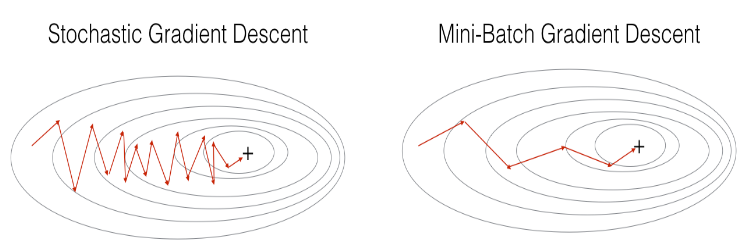
MBGD 比 SGD 的震荡更小:
划分 mini -batch 的步骤
一共有两步:
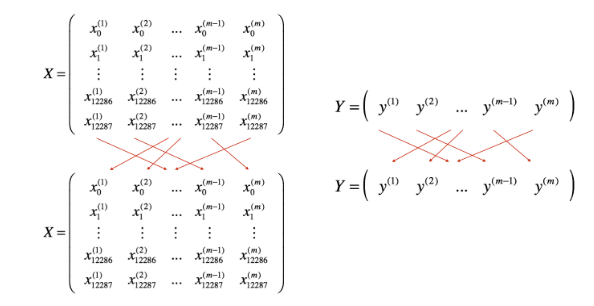
洗牌 (shuffle):将训练集 (X,Y)进行随机的洗牌,打乱每一列的顺序,确保所有的样本会被随机分成不同的小批次。注意 X 和 Y 需要进行一样的洗牌操作,一一对应,如下图所示。
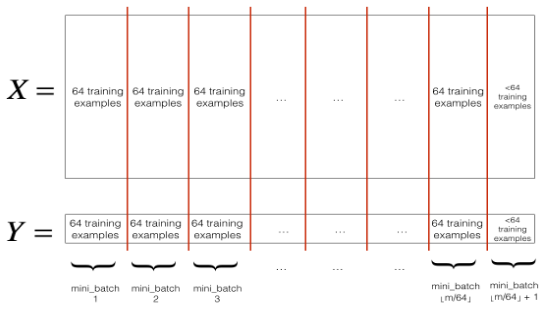
划分 (Partition):将训练集划分为每个大小为 mini_batch_size 的小批次。注意总样本数不一定总是能被 mini_batch_size 整除,所以最后一个小批次比 mini_batch_size 要小,如下图所示。
实现
1 | def random_mini_batches(X, Y, mini_batch_size = 64): |
动量梯度下降
由于小批量梯度下降也会产生震荡问题,所以我们采用动量算法,考虑之前几次迭代的梯度来减小震荡。
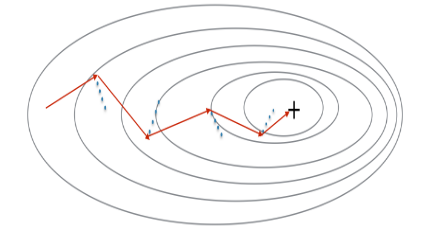
蓝色线是每一次梯度的方向,但是每次下降不沿着梯度方向走,而是沿着红线走,它是前几次梯度方向的加权平均值 v ——称之为“速度”。
初始化 v
1 | def initialize_velocity(parameters): |
更新参数
1 | def update_parameters_with_momentum(parameters, grads, v, beta, learning_rate): |
Adam 算法
Adam 是训练神经网络最有效的算法之一,结合了动量算法和 RMSprop 算法的优点。
一共三步:
- 计算之前梯度的指数加权平均 v,然后其计算偏差修正值 v_correct
- 计算之前梯度的平方的指数加权平均 s,然后计算其偏差修正值 s_correct
- 用上面的值更新参数
公式:
初始化 v 和 s
1 | def initialize_adam(parameters) : |
用 v 和 s 更新参数
1 | def update_parameters_with_adam(parameters, grads, v, s, t, learning_rate = 0.01,beta1 = 0.9, beta2 = 0.999, epsilon = 1e-8): |
比较几种优化算法的区别
- 使用普通的批量梯度下降,调用函数:
- update_parameters_with_gd()
- 使用动量算法梯度下降,调用函数:
- initialize_velocity() 和 update_parameters_with_momentum()
- 使用 Adam 梯度下降,调用函数:
- initialize_adam() 和 update_parameters_with_adam()
1 | def model(X, Y, layers_dims, optimizer, learning_rate = 0.0007, mini_batch_size = 64, beta = 0.9,beta1 = 0.9, beta2 = 0.999, epsilon = 1e-8, num_epochs = 10000, print_cost = True): |
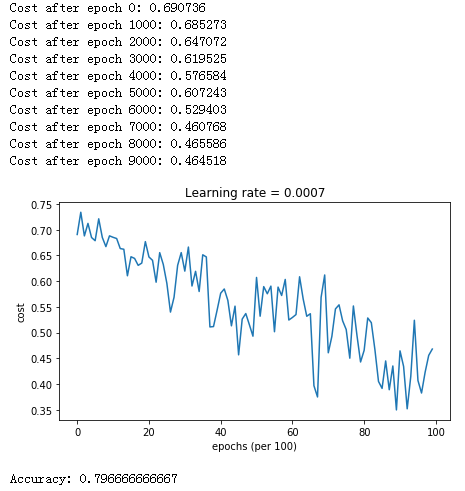
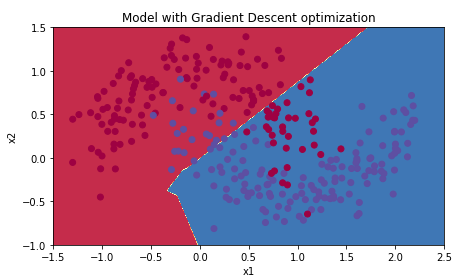
使用 MBGD
1 | # train 3-layer model |
结果如下:
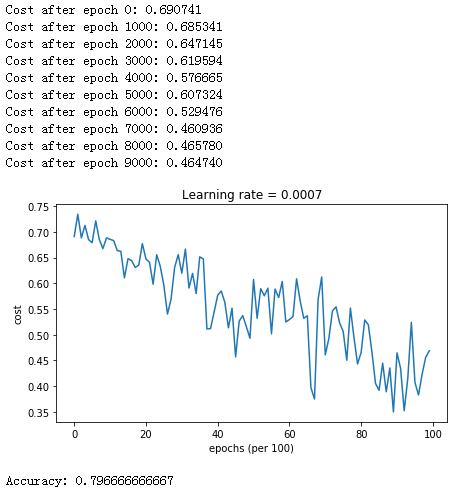
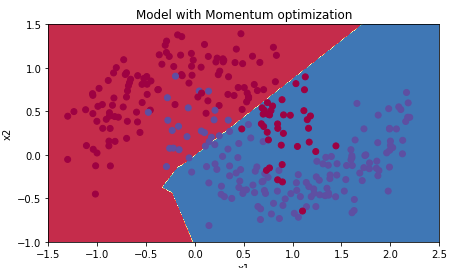
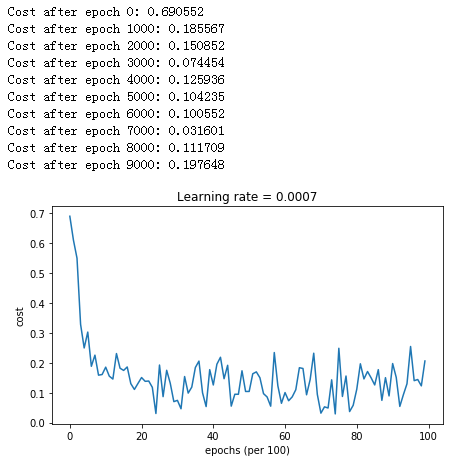
使用动量算法
1 | # train 3-layer model |
结果:
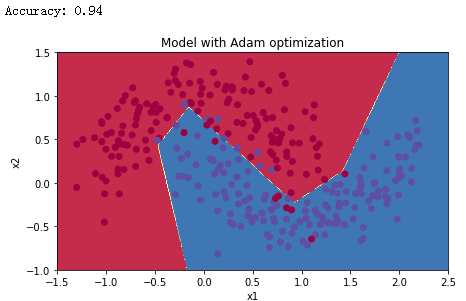
使用 Adam 算法
1 | # train 3-layer model |
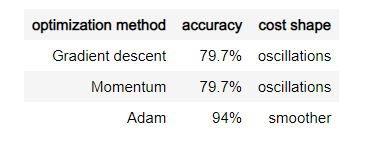
总结
- 动量算法经常会有帮助,但是在小学习率和简单的的数据集中它的影响几乎可以忽略。
- 代价函数的震荡是因为某些小批次的数据噪声更多
- Adam 算法比动量算法和 MBGD 表现精确度更高,但是如果给足够的时间,三个算法都会得到很好的精确度,但是这说明 Adam 算法运行更快
- Adam 算法的优点
- 虽然比动量算法和 MBGD 所需的内存更多,但是相对来说所需内存还是较少
- 几乎不需要怎么调整它的超参数 $\beta_1,\beta_2,\varepsilon$ ,直接使用默认值,就能得到很好的结果

