defsigmoid(x): """ Compute the sigmoid of x Arguments: x -- A scalar or numpy array of any size Return: s -- sigmoid(x) """ s = 1 / (1 + np.exp(-x)) return s
defsigmoid_derivative(x): """ Compute the gradient (also called the slope or derivative) of the sigmoid function with respect to its input x. You can store the output of the sigmoid function into variables and then use it to calculate the gradient. Arguments: x -- A scalar or numpy array Return: ds -- Your computed gradient. """
X.reshape 命令用于把 X 重构为某个维度,例如把 shape (length,height,depth=3) 的图片变成输入,重构为 shape (length∗height∗3,1) 的向量
下面的代码把一张图片变为一个向量:
1 2 3 4 5 6 7 8 9 10 11 12 13
defimage2vector(image): """ Argument: image -- a numpy array of shape (length, height, depth) Returns: v -- a vector of shape (length*height*depth, 1) """ v = image.reshape((image.shape[0]*image.shape[1]*image.shape[2],1)) #image.shape[0] 获得图片或数组第一个维度的长度 return v
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# This is a 3 by 3 by 2 array, typically images will be (num_px_x, num_px_y,3) where 3 represents the RGB values image = np.array([[[ 0.67826139, 0.29380381], [ 0.90714982, 0.52835647], [ 0.4215251 , 0.45017551]],
defnormalizeRows(x): """ Implement a function that normalizes each row of the matrix x (to have unit length). Argument: x -- A numpy matrix of shape (n, m) Returns: x -- The normalized (by row) numpy matrix. You are allowed to modify x. """ x_norm = np.linalg.norm(x, ord = 2,axis = 1,keepdims = True) #计算 x 的范数或者说行向量的模,其中 ord = 2 表示范数类型为 2,即平方和的开方,axis =1 表示按行向量处理,keepdims = True 表示保持矩阵的二维特性 x = x / x_norm #用 x 矩阵除以行向量的模,自动进行广播拓展 return x
$\text{for a matrix } x \in \mathbb{R}^{m \times n} \text{, $x_{ij}$ maps to the element in the $i^{th}$ row and $j^{th}$ column of $x$, thus we have: }$
defsoftmax(x): """Calculates the softmax for each row of the input x. Your code should work for a row vector and also for matrices of shape (n, m). Argument: x -- A numpy matrix of shape (n,m) Returns: s -- A numpy matrix equal to the softmax of x, of shape (n,m) """ # 对 x 每个元素求 exp() x_exp = np.exp(x)
defL1(yhat, y): """ Arguments: yhat -- vector of size m (predicted labels) y -- vector of size m (true labels) Returns: loss -- the value of the L1 loss function defined above """
defL2(yhat, y): """ Arguments: yhat -- vector of size m (predicted labels) y -- vector of size m (true labels) Returns: loss -- the value of the L2 loss function defined above """
# 初始化参数 definitialize_with_zeros(dim): """ This function creates a vector of zeros of shape (dim, 1) for w and initializes b to 0. Argument: dim -- size of the w vector we want (or number of parameters in this case) Returns: w -- initialized vector of shape (dim, 1) b -- initialized scalar (corresponds to the bias) """
w = np.zeros((dim,1)) b = 0
assert(w.shape == (dim, 1)) # 确保 w 的维度正确 assert(isinstance(b, float) or isinstance(b, int)) #确保 b 是浮点数或者整数 return w, b
1 2 3 4
dim = 2 w, b = initialize_with_zeros(dim) print ("w = " + str(w)) print ("b = " + str(b))
# 计算前向传播和反向传播 defpropagate(w, b, X, Y): """ Implement the cost function and its gradient for the propagation explained above Arguments: w -- weights, a numpy array of size (num_px * num_px * 3, 1) b -- bias, a scalar X -- data of size (num_px * num_px * 3, number of examples) Y -- true "label" vector (containing 0 if non-cat, 1 if cat) of size (1, number of examples) Return: cost -- negative log-likelihood cost for logistic regression dw -- gradient of the loss with respect to w, thus same shape as w db -- gradient of the loss with respect to b, thus same shape as b Tips: - Write your code step by step for the propagation. np.log(), np.dot() """ m = X.shape[1] # 前向传播 (从 X 到 COST) A = sigmoid(np.dot(w.T,X ) + b) # 计算预测值 cost = (-1/m)*(np.sum(Y*np.log(A) + (1-Y)*np.log(1-A))) # 计算代价函数 # 反向传播 (计算梯度) dw = (1/m)*np.dot(X,(A-Y).T) db = (1/m)*np.sum(A-Y)
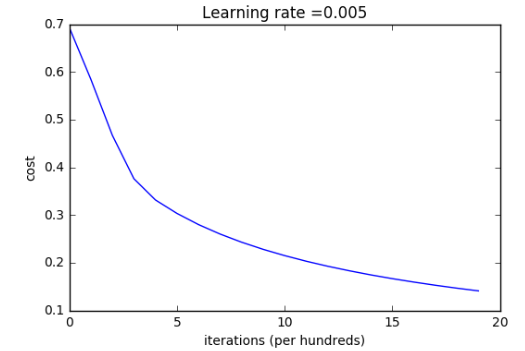
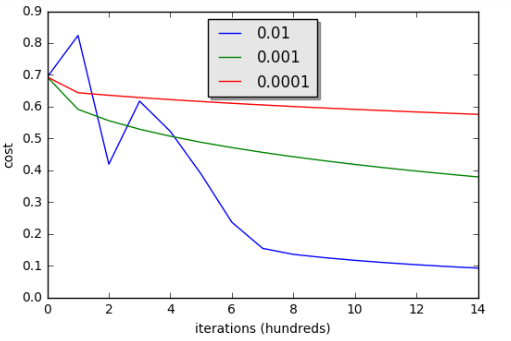
#梯度下降 defoptimize(w, b, X, Y, num_iterations, learning_rate, print_cost = False): """ This function optimizes w and b by running a gradient descent algorithm Arguments: w -- weights, a numpy array of size (num_px * num_px * 3, 1) b -- bias, a scalar X -- data of shape (num_px * num_px * 3, number of examples) Y -- true "label" vector (containing 0 if non-cat, 1 if cat), of shape (1, number of examples) num_iterations -- 循环的迭代次数 learning_rate -- 学习率 print_cost -- True to print the loss every 100 steps Returns: params -- dictionary containing the weights w and bias b grads -- dictionary containing the gradients of the weights and bias with respect to the cost function costs -- list of all the costs computed during the optimization, this will be used to plot the learning curve. Tips: You basically need to write down two steps and iterate through them: 1) Calculate the cost and the gradient for the current parameters. Use propagate(). 2) Update the parameters using gradient descent rule for w and b. """ costs = [] for i in range(num_iterations): # 代价函数和梯度计算 grads, cost = propagate(w, b, X, Y) dw = grads["dw"] db = grads["db"] # 更新参数 w = w - learning_rate*dw b = b - learning_rate*db
# 每100次迭代记录一次代价函数到 costs if i % 100 == 0: costs.append(cost) # 每一百步打印一次代价函数 if print_cost and i % 100 == 0: print ("Cost after iteration %i: %f" %(i, cost)) params = {"w": w, "b": b} grads = {"dw": dw, "db": db} return params, grads, costs
# 进行预测 defpredict(w, b, X): ''' Predict whether the label is 0 or 1 using learned logistic regression parameters (w, b) Arguments: w -- weights, a numpy array of size (num_px * num_px * 3, 1) b -- bias, a scalar X -- data of size (num_px * num_px * 3, number of examples) Returns: Y_prediction -- a numpy array (vector) containing all predictions (0/1) for the examples in X ''' m = X.shape[1] Y_prediction = np.zeros((1,m)) #初始化 w = w.reshape(X.shape[0], 1) #确保 w shape 正确 # 计算图片中是猫的概率 A = sigmoid(np.dot(w.T,X) + b) for i in range(A.shape[1]): # 把概率转化为标签值 if A[0,i] > 0.5: Y_prediction[0,i] = 1 else: Y_prediction[0,i] = 0 assert(Y_prediction.shape == (1, m)) return Y_prediction
1 2 3 4
w = np.array([[0.1124579],[0.23106775]]) b = -0.3 X = np.array([[1.,-1.1,-3.2],[1.2,2.,0.1]]) print ("predictions = " + str(predict(w, b, X)))
# 主函数 defmodel(X_train, Y_train, X_test, Y_test, num_iterations = 2000, learning_rate = 0.5, print_cost = False): """ Builds the logistic regression model by calling the function you've implemented previously Arguments: X_train -- training set represented by a numpy array of shape (num_px * num_px * 3, m_train) Y_train -- training labels represented by a numpy array (vector) of shape (1, m_train) X_test -- test set represented by a numpy array of shape (num_px * num_px * 3, m_test) Y_test -- test labels represented by a numpy array (vector) of shape (1, m_test) num_iterations -- hyperparameter representing the number of iterations to optimize the parameters learning_rate -- hyperparameter representing the learning rate used in the update rule of optimize() print_cost -- Set to true to print the cost every 100 iterations Returns: d -- dictionary containing information about the model. """
# 用 0 初始化参数 w, b = initialize_with_zeros(X_train.shape[0])
# Example of a picture that was wrongly classified. index = 1 plt.imshow(test_set_x[:,index].reshape((num_px, num_px, 3))) print ("y = " + str(test_set_y[0,index]) + ", you predicted that it is a \"" + classes[d["Y_prediction_test"][0,index]].decode("utf-8") + "\" picture.")